3 月 27 日,Anthropic 一个没上锁的数据缓存泄露了约 3000 份内部文件。其中一篇草稿博文透露了正在内测的新模型 Mythos,Anthropic 自己的评价是「在网络安全能力上远超目前任何 AI 模型」。同一天,CrowdStrike 和 Okta 各跌 7%,Palo Alto Networks 跌 6%。
市场的恐慌不是因为又出了一个更强的模型。而是这个模型的制造者说,它在攻击端的进步速度,已经快过防御端能跟上的速度。
AI 网络安全能力一家独大
据学术基准 CAIBench 的测试结果,在模拟真实攻防环境的 Cybench 测试中,Claude Sonnet 4.5 的成功率为 46%。排名第二的 GPT-5 是 28%,谷歌的 Gemini 2.5 Pro 只有 18%,开源模型 qwen3-32B 更低至 10%。
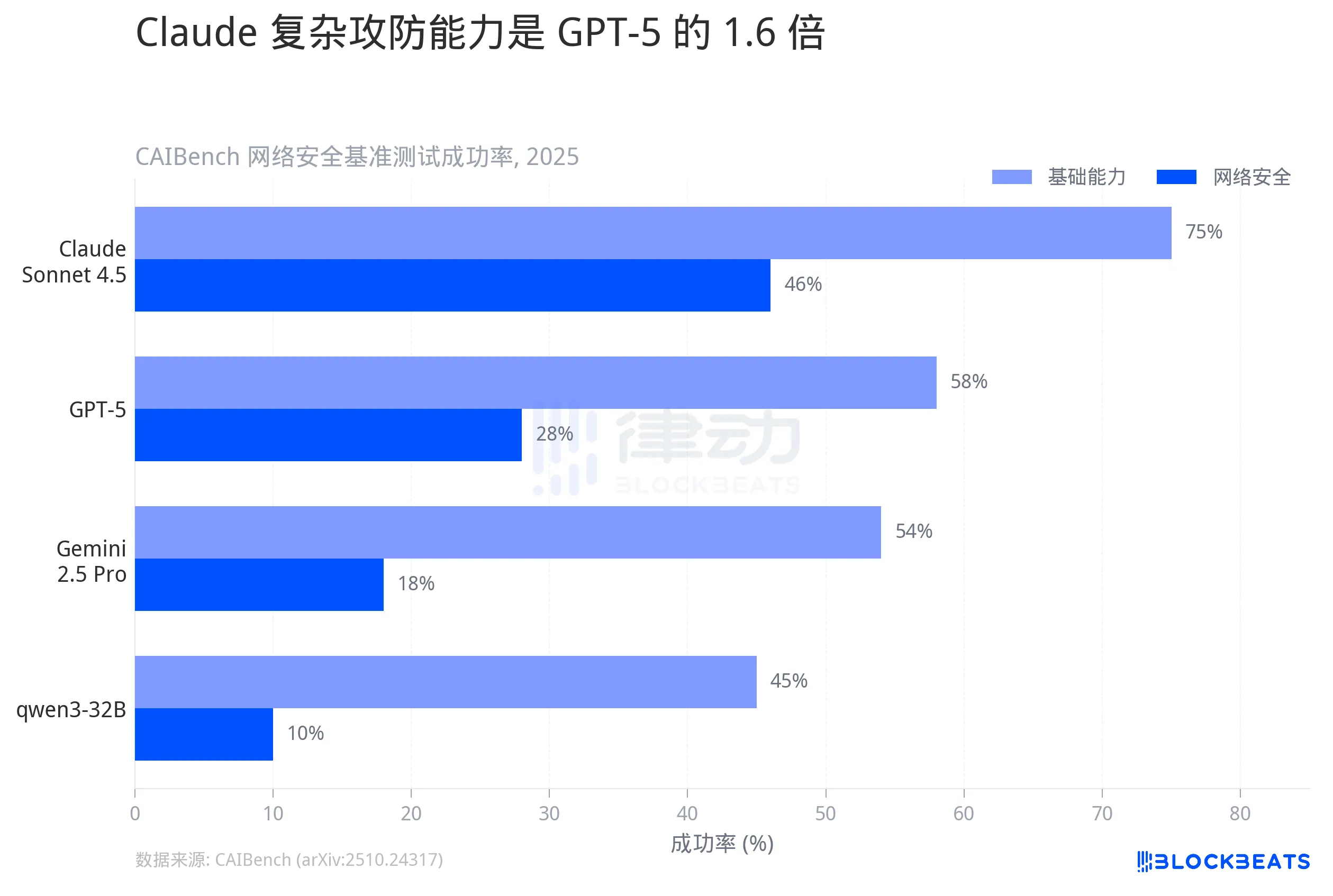
46% 看起来不算高,但这是复杂渗透任务的成功率,包含漏洞发现、利用链构建和权限提升等多步骤操作。在更基础的 Base 测试中,Claude 的成功率已经达到 75%,接近天花板。
差距不在于「谁更好一点」,在于量级。Claude 的复杂攻防能力是 GPT-5 的 1.6 倍,是 Gemini 的 2.5 倍。在网络安全这个维度上,模型之间的能力分布不是梯队,是断层。
6 个月翻倍
更值得拆的不是横向差距,是纵向速度。
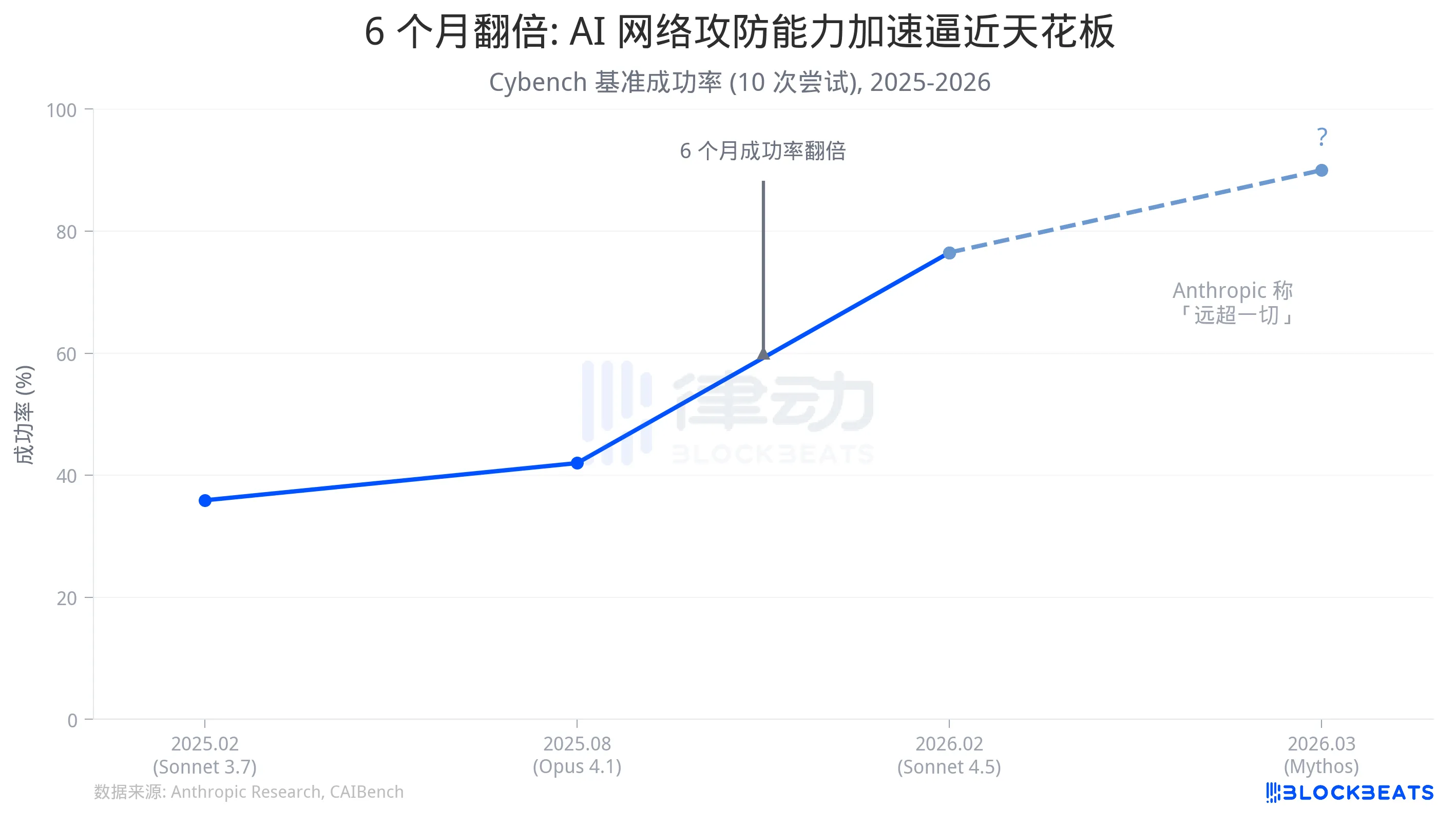
据 Anthropic 官方数据,2025 年 2 月发布的 Sonnet 3.7 在 Cybench 上的成功率是 35.9%(10 次尝试)。同年下半年发布的 Sonnet 4.5 达到 76.5%。Anthropic 研究团队的统计是:6 个月内,成功率翻倍。
这个速度意味着什么?拿真实场景对比:Claude Opus 4.6 在今年 3 月被用于审计 Firefox 代码库,据 InfoQ 报道,两周内发现了 22 个安全漏洞,其中 14 个高危。这些漏洞此前经过多年人工审计和数百万小时 CPU 模糊测试,一直没被发现。Anthropic 的安全团队此前还披露,Claude 在多个生产级开源项目中发现了超过 500 个高危漏洞,部分存在数十年。
而传统渗透测试的行业标准周期是 2 到 3 周,而且这还只是测一个应用。据 Verizon 2025 年数据泄露调查报告,关键漏洞从公开到被攻击者大规模利用的中位时间是 5 天,修复中位时间是 32 到 38 天。
AI 找漏洞的速度在指数级增长,人类补漏洞的速度是线性的。中间的时间差就是攻击窗口。
泄露的 Mythos 草稿中,Anthropic 写道,这个模型「预示着即将到来的一波模型,能以远超防御者努力的方式利用漏洞」。基于已公开的能力曲线,这不是夸张。
发得越快,警告越急
把 Anthropic 过去三年的动作排在一张时间线上,会看到一个清晰的模式:每次发布更强的模型,紧接着就是更高级别的安全响应。
2023 年 7 月签署白宫自愿承诺,同年 9 月发布第一版负责任扩展政策(RSP v1.0)。2024 年 10 月 RSP 升级到 v2.0,新增了生化武器能力阈值。2025 年 11 月,Anthropic 披露了 GTG-1002 事件。一个中国国家支持的威胁组织利用 Claude Code 渗透了约 30 个组织,AI 在整个行动中独立执行了 80% 到 90% 的战术操作。这是有记录以来第一次大规模 AI 编排的网络间谍行动。
2026 年 2 月,RSP 更新到 v3.0,Claude Code Security 同步发布。同月,五角大楼因 Anthropic 拒绝取消合同中关于禁止大规模监控和全自主武器的限制条款,将其列为「供应链风险」。一个月后,Mythos 泄露,Anthropic 在草稿中承认这个模型具有「前所未有的网络安全风险」。

能力发布在加速。从 Claude 1 到 Claude 3 间隔一年,从 Opus 4.5 到 Opus 4.6 间隔不到三个月。安全响应也在加速,但始终是被动的:先有能力突破,再有政策补丁。3 月 27 日网络安全股的集体下跌,定价的就是这个时间差。
Dark Reading 今年初的调查显示,48% 的网络安全从业者将智能体 AI 列为 2026 年头号攻击向量。两年前,这个选项几乎不在榜单前列。
Anthropic 的 Mythos 发布策略是先给防御方组织提供早期访问,「给他们一个先发优势」。这句话本身就是对攻防不对称的确认。如果防御者不需要先发优势,说明攻击者还没到门口。