谷歌威胁情报组表示,其识别出它认为是黑客首次利用人工智能开发零日漏洞利用的案例。
该团队在周二的一篇博客文章中表示,已“观察到知名网络犯罪威胁行为者相互合作,策划大规模漏洞利用行动”,并使用一个零日漏洞绕过某款未具名“流行的开源、基于网页的系统管理工具”的双因素认证。
该漏洞利用首先需要有效的用户凭证,但绕过了第二重认证因素,而这类因素也常用于保护加密账户和钱包。
人工智能正越来越多地被用于网络安全领域,也被寻求实施攻击或诈骗的加密黑客使用。人工智能公司 Anthropic 上月声称,其最新 AI 模型 Claude Mythos 发现了数千个软件漏洞,覆盖多个主要系统。
谷歌表示,其“高度确信该行为者很可能借助 AI 模型来支持发现并武器化这一漏洞”,因为该漏洞利用脚本中包含一个幻觉内容,以及一种“高度符合”AI 模型训练数据特征的格式。
报告未指明具体威胁行为者,但谷歌表示,中国和朝鲜“已表现出对利用 AI 进行漏洞发现的浓厚兴趣”。
LLM 擅长高层级缺陷识别
谷歌表示,该漏洞并非源于“常见实现错误”,如内存破坏,而是源于开发者硬编码信任假设所导致的“高层级语义逻辑缺陷”。
谷歌补充称,这意味着攻击者使用了前沿大语言模型(LLM),因为这类模型擅长识别高层级缺陷和“硬编码静态异常”。
谷歌表示,PROMPTFLUX、HONESTCUE 和 CANFAIL 等多个恶意软件家族也在使用 LLM 进行防御规避,通过生成诱饵或填充代码来掩盖恶意逻辑。
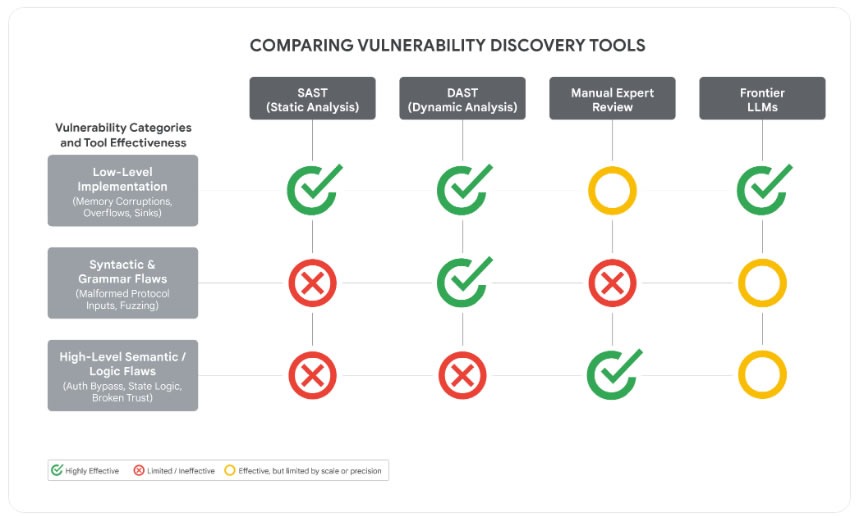
LLM 漏洞发现能力与其他发现机制的对比。来源: 谷歌
工业化的 LLM 滥用正在增加
随着威胁行为者建立自动化流程,循环使用高级 AI 账户、汇集 API 密钥,并大规模绕过安全护栏,LLM 访问滥用正变得工业化——实际上是在利用试用账户滥用来补贴对抗性操作。
“通过利用反检测浏览器和账户池服务,行为者正试图维持对高级 LLM 层级的高频、匿名访问,从而有效地将其对抗性工作流程工业化。”
谷歌总结称,随着各组织继续将 LLM 整合到生产环境中,AI 软件生态系统已成为首要攻击目标。
该公司指出,攻击者正越来越多地瞄准赋予 AI 系统实用性的集成组件,例如自主技能和“第三方数据连接器”,但威胁行为者尚未取得突破性能力来绕过前沿模型的核心安全逻辑。