TL;DR
过去几年,AI 基础设施的主角一直是 GPU。谁拿到更多 H100、B200,谁就有更强的算力供给。但进入 Rubin 和后续平台,投资者需要多看一层:GPU 能不能装进机柜,机柜能不能稳定供电,热量能不能带走,出厂前能不能满载测试。
800VDC 开始被市场讨论,原因就在这里。英伟达自 2025 年以来持续公开推动 800VDC 架构,并把它放进下一代 AI factory 和高功率机柜的设计方向里。表面看,这是电压规格从传统低压向高压直流迁移。往里看,AI 服务器不再只是板卡和芯片的组装,越来越像一项电力工程。
普通投资者可以这样理解:一整柜 AI 服务器就像一栋用电极高的小楼。过去的供电方式还能支撑几十千瓦、上百千瓦的机柜,但当功率继续上升,问题就不只是「买多少 GPU」,而是电怎么送进去、热怎么散出去、机器出厂前怎么连续满载跑起来。
高功率机柜正在逼近低压供电边界
这一轮变化的起点,是 AI 机柜功率上升太快。传统服务器机柜可能只有几千瓦到十几千瓦,到了英伟达GB200、GB300 一代,整柜功率已经进入百千瓦级别。据 Tom’s Hardware 报道,GB200/GB300 NVL72 约为 120-140kW。
Rubin 之后,功率密度还可能继续抬升。部分供应链和行业测算认为,Rubin NVL72 可能进一步来到约 180-220kW。这个区间并非英伟达官方确认口径,仍应视作第三方估算,但方向已经清楚:前沿 AI 机柜正在变成更高密度的用电单元。
电力问题可以用一个公式解释:功率等于电压乘以电流。同样要送 600kW 的电,如果电压较低,就必须使用更大的电流。电流越大,线缆和铜排越粗,发热越严重,电能在线路里的损耗也越高。
传统低压供电像是用很粗的水管慢慢送大量水。能送,但管子越来越粗、越来越重、越来越占空间。机柜空间本来应该留给 GPU、内存、网络和散热结构,却被电源架、线缆、铜排挤占。到数百千瓦乃至更高功率级别,继续堆低压大电流会变得越来越不经济。
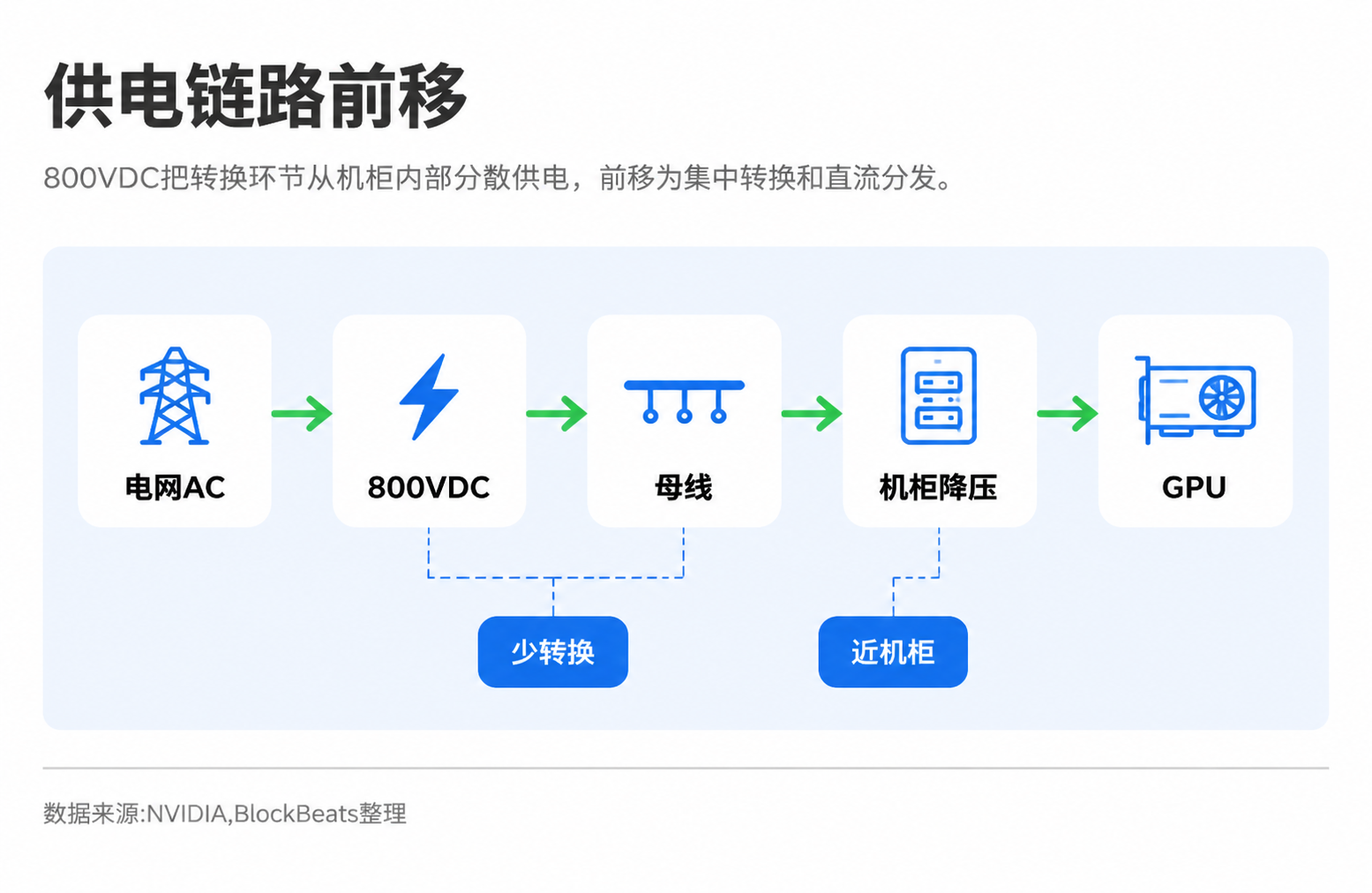
800VDC 的思路是提高电压,把电更高效地送到机柜附近,再在本地降压给 GPU 使用。它像是把水压提高,用更细的管道输送同样多的水。英伟达官方材料称,800VDC 可以减少电流、铜用量、线缆体积和转换环节,效率最高提升 5%,TCO 最高改善 30%。部分第三方和伙伴测算还提到,铜用量可能下降约 45%,实际收益取决于数据中心和机柜集成方式。
这不是单纯为了省铜。对英伟达来说,800VDC 的核心价值是让下一代 AI 机柜还能继续增加计算密度。低压系统不是不能用,但在最高密度的 AI factory 里,它开始接近工程边界。
英伟达用参考架构重划基础设施分工
英伟达重要的地方,不只是提出一个电压方案,而是用参考架构重新定义生态分工。自 2025 年起,英伟达多次公开介绍 800VDC 架构,并在技术博客和 OCP 等场合展示面向 Rubin、Kyber rack 等高功率系统的设计方向。
据英伟达官方博客,其 800VDC 生态伙伴包括台达电、施耐德电气、Vertiv、英飞凌、意法半导体等,也包括 ABB、伊顿、GE Vernova、Hitachi Energy、西门子、Navitas、德州仪器等公司。这里更准确的说法是生态合作和适配,不能直接理解成订单已经落地。
800VDC 涉及的不是单个零部件升级,而是从数据中心配电、机柜电源、备用电池、功率器件、连接器到整柜集成的一整条链路变化。过去电力转换可能分散在 UPS、PDU、服务器电源、主板供电等多个环节。高压直流架构下,电力更接近机柜,再由机柜内或 GPU 附近的模块降压。
价值链里的权重也会随之变化。传统服务器时代,投资者更关注 GPU、CPU、内存和整机代工。高功率 AI 机柜时代,电源架、母线、连接器、功率半导体、液冷系统和整柜验证能力,都开始变成交付能力的一部分。
边界也要说清楚。800VDC 更像是前沿高密度 AI factory 的重要参考架构,不是所有数据中心马上统一切换的标准。大量既有数据中心仍会继续使用传统交流或混合架构,新建项目也会根据功率密度、成本、业主改造意愿和安全规范分层采用。市场真正交易的,不是今年全部换成 800V,而是 2027 年以后最高密度 AI 机柜的基础设施规则正在变化。
电源、连接、液冷和整柜测试被推到台前
从投资角度看,800VDC 最直接的影响,是让原本偏后台的基础设施环节走到台前。
第一类是电源基础设施公司,例如 Vertiv、施耐德电气、台达电,以及部分韩国和中国台湾电力设备厂商。它们不只是卖传统机房电力设备,而是要参与新一代 AI factory 的配电、机柜供电、备用电池和高压直流系统设计。据 Asia Business Daily 报道,英伟达与 LS Electric、HD Hyundai Electric、Hyosung 等韩国电力设备公司围绕 800VDC 数据中心基础设施进行沟通。该报道基于业内人士信息,不能等同于订单落地,但能说明电力设备商正在被纳入 AI factory 生态。
第二类是功率器件,也就是 SiC/GaN(碳化硅/氮化镓)等新一代电力开关。它们比传统硅器件更适合高压、高频、高效率场景,过去常被放在电动车、充电桩、工业电源的框架下讨论,如今正在外溢到 AI 数据中心。英飞凌、意法半导体等公司因此进入投资者视野。但功率半导体的受益还取决于具体设计、供应份额、价格和良率,不能简单等同于「800VDC 概念股」。
第三类是连接和机械结构,包括铜排、母线、高压连接器、高端背板和部分厚铜、高层 PCB。电压升高后,电流下降,铜耗压力缓解,但绝缘、安全、连接可靠性和结构设计的要求更高。低端铜材并不天然受益,真正有价值的是能适配高功率、高可靠性机柜的连接与供电材料。
第四类是液冷和整柜 ODM。功率上去后,散热不再是附属问题。服务器要在客户机房稳定运行,必须在出厂前完成整柜级测试,包括供电、散热、网络和 GPU 满载稳定性。戴尔、Wiwynn、纬创等整柜交付方,竞争的不只是组装效率,还包括是否有足够电力、场地、液冷测试和系统调校能力。
设计方向清楚,交付能力还要实测
英伟达已经给出清晰的技术方向,但供应链执行不会自动顺滑。这里的张力,正是投资者需要跟踪的地方。
独立供应链分析师 Dan Nystedt 近期多次转述中国台湾媒体和产业信息:AI 服务器 ODM 营收强劲,Rubin 相关生产准备推进,但零部件、电力基础设施和整柜 burn-in 测试(满载老化测试)正在成为现实约束。所谓 burn-in,可以理解为服务器出厂前的压力测试。整柜 GPU 长时间满载运行,供电、散热和系统稳定性都要一起过关。
单柜如果需要 100-200kW 级别持续供电,测试工厂本身就要具备接近小型数据中心的电力和冷却能力。这类供应链信号不能写成行业已经普遍自备发电,也不能直接推导为供电已经取代 GPU 成为最大瓶颈。它更像一个提醒:Rubin 时代的交付,不只是 GPU 到货和主板装配,而是电力、液冷、测试和整柜稳定性一起到位。
部分 ODM、电力设备和液冷公司被重新定价,逻辑也在这里。它们的价值不只来自参与 AI 服务器,而来自能否把高功率机柜可靠地交付给云厂商。未来如果同样拿到英伟达参考设计,真正拉开差距的可能是测试场地、电力容量、液冷调试经验和交付良率。
对 CoreWeave、Nebius 等 AI 云厂商来说,800VDC 不是直接的零部件受益逻辑,而是资本开支效率和上线速度的变量。高密度机柜能否按时部署,会影响算力交付、折旧节奏和收入兑现。Marvell、Lumentum 等高速互连或光模块链条,则更多属于 AI 集群扩张的并行逻辑,不宜和 800VDC 直接受益混在一起。
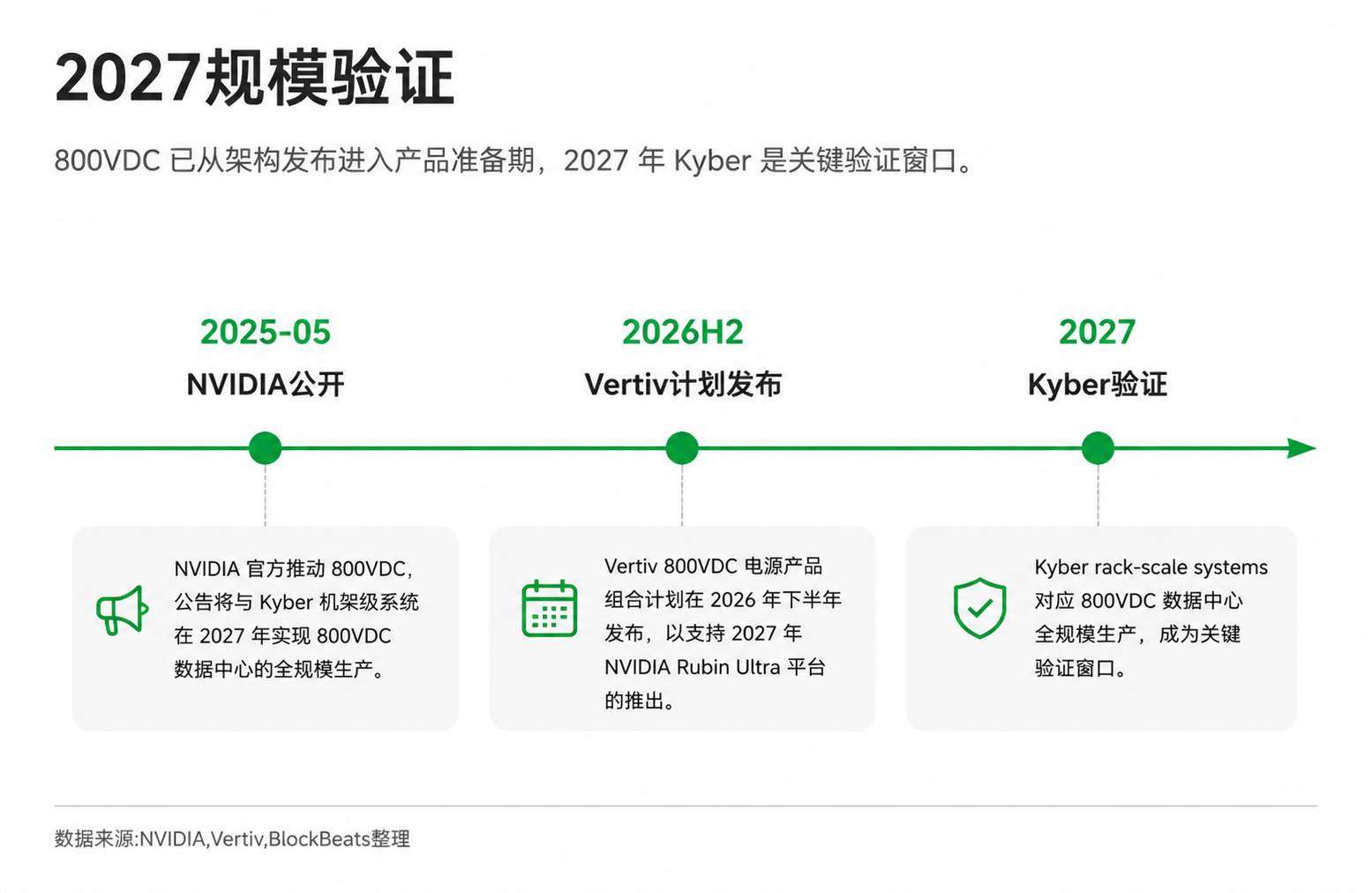
2027 年看 Kyber 机柜和订单兑现
800VDC 的方向已经比一年前清楚得多:英伟达官方推动,伙伴生态适配,物理约束存在,前沿高密度 AI factory 需要更高效的供电方式。但它现在仍处于准备和早期部署窗口。英伟达官方称,800VDC 全规模生产将与 2027 年 Kyber rack-scale systems 对应,真正验证还要看后续产品和客户项目能否落地。
接下来最值得看的,不是某家公司是否在公告里提到「AI 电力」,而是有没有明确进入 800VDC 相关产品、客户验证和订单交付。ODM 是否披露更强的整柜测试能力,液冷系统在长时间满载下的可靠性如何,数据中心业主是否愿意为高压直流架构改造配电和安全规范,都会影响这条交易的节奏。
如果 Rubin 相关机柜顺利爬坡,且 800VDC 组件订单从样品、验证走向规模采购,市场会继续提高供电、液冷、连接器和整柜交付能力的权重。反过来,如果功耗配置低于预期,客户采用更保守的混合架构,或者测试电力与液冷可靠性拖慢交付,800VDC 交易也会从方向判断回到订单和节奏验证。GPU 仍是核心,但在 Rubin 之后,能不能把一整柜高功率系统稳定交付,已经开始变成资产定价变量。