编者按:Anthropic 的 Lance Martin 认为,Claude Fable 5 这类 Mythos 级模型的关键用法,不是靠人不断手动提示,而是为模型设计可自我纠错的循环。
文章提出两个核心技巧:一是通过 /goal、Outcomes 等机制设置明确目标或评分标准,让模型在执行、接收反馈、修正方案之间持续迭代;二是利用 memory(跨会话记忆)让模型记录失败、调查原因、验证结论,并把经验提炼成未来可复用的规则。
在 Parameter Golf 和 Continual Learning Bench 等实验中,Fable 5 相比 Opus 4.7、Sonnet 4.6 更擅长进行结构性探索、坚持长期任务,并把记忆转化为后续任务的有效改进。
文章的核心观点是:与其直接操控模型,不如设计环境、反馈机制和记忆系统,让模型自己在循环中变强。
以下为原文:
像 Claude Fable 5 这样的 Mythos 级模型,已经改变了 Anthropic 内部许多人的工作方式。我想分享两个技巧,帮助大家更好地发挥这类模型的能力。
自我纠错循环
最近,大家对「循环(Loop)」很感兴趣。@bcherny 曾提到,「我的工作就是写循环。」让模型围绕某个评估标准不断爬坡优化,是提升任务表现的常见方法:Claude Code 里的 /goal,以及 Claude Managed Agent 里的 Outcomes,都是可以让你把这一通用方法应用到具体任务中的基础能力。
正如我们在 Prompt 指南中提到的,Fable 5 很擅长在循环中进行自我纠错。一个设计良好的目标或评分标准,相当于给 Claude 所处的环境增加了反馈机制。这样,Claude 就可以先执行任务,再通过目标或评分标准收集反馈,随后自我修正,并持续推进,直到满足目标或评分标准为止。

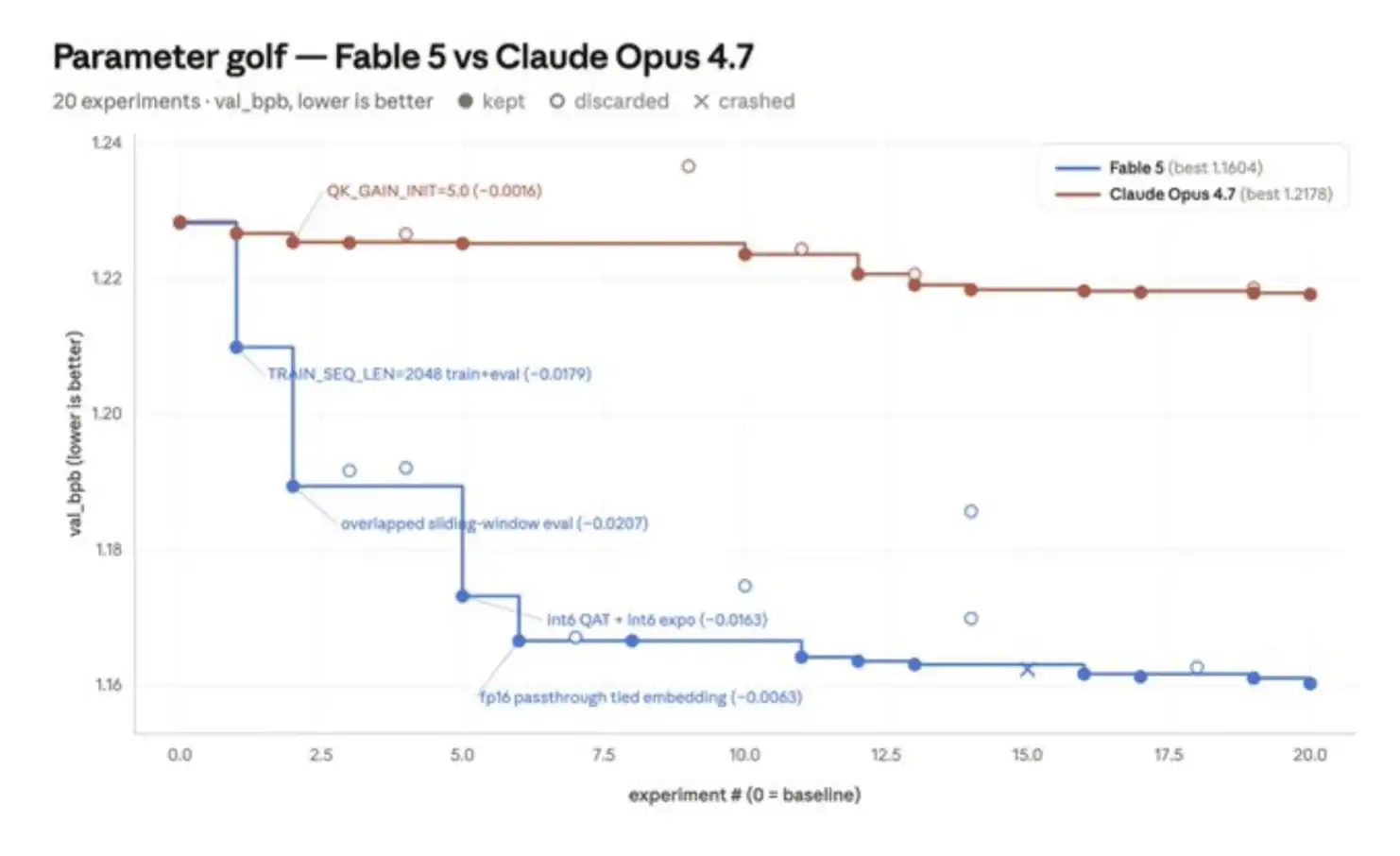
我分享一个自己用来测试 Fable 的小例子:Parameter Golf。这是一个开源的机器学习工程挑战,目标是在 8 张 H100 GPU 上、10 分钟以内,训练出一个效果最好的模型,并且最终产物必须控制在 16MB 以内。
它有点像 @karpathy 的 autoresearch 项目:这个挑战测试的是一个 Agent 是否有能力修改基础训练代码,也就是一个 train_gpt.py 文件;启动训练;轮询日志;读取分数;并决定下一步该运行什么实验。
我用 Claude Managed Agents(CMA)在这个挑战上对比了 Fable 5 和 Opus 4.7。CMA 提供 Agent 运行框架和托管沙盒,因此非常适合让 Fable 5 执行长周期任务。在 Parameter Golf 这个测试里,我让 CMA 接入了一个自托管沙盒,其中包含 8 张 H100 GPU。
这里有一个微妙但重要的点:由谁来评判结果很关键。我们发现,模型在批判自己生成的内容时往往会出现问题。Prithvi Rajasekaran 曾在我们的工程博客中写过这一点。
我们发现,对于 Fable 5 来说,使用一个验证型子 Agent,通常比让模型自我批判效果更好,因为评分是在一个独立的上下文窗口中完成的。CMA 里的 Outcomes 功能会自动为你启动一个评分子 Agent 来处理这件事。
在每次测试中,我都会提供一个评分标准文件,其中包含九项可检查的标准,比如运行基线实验、完成 20 次实验等。随后,我让 Parameter Golf 最多运行 8 小时。只有当 Outcomes 评分器确认所有实验标准都已满足之后,Claude 才被允许停止工作。
结果是,Fable 5 对训练流程的改进幅度大约是 Opus 4.7 的 6 倍。如果把实验分为结构性实验,比如改变模型架构,和标量型实验,比如调整某个常数,那么 Fable 5 更倾向于押注更大的结构性改动,并且表现出了更强的韧性。例如,它在一次量化回归问题中坚持推进,最终取得了最大的一次提升。
相比之下,Opus 4.7 的第一次实验带来了一点小幅提升,但之后几乎所有实验都沿用了同一种模板:调整一个标量,测量结果,如果结果为正就保留。
记忆
记忆是 Fable 擅长的另一个领域。我们可以把它理解为一种跨会话运行的外部循环:Claude 会在一次会话中写入记忆,而这些记忆可以在未来的会话中被再次检索出来。
@pgasawa 和团队最近发布了 Continual Learning Bench 1.0,所以我也想用它来测试 Fable 5 和早期模型之间的差异。

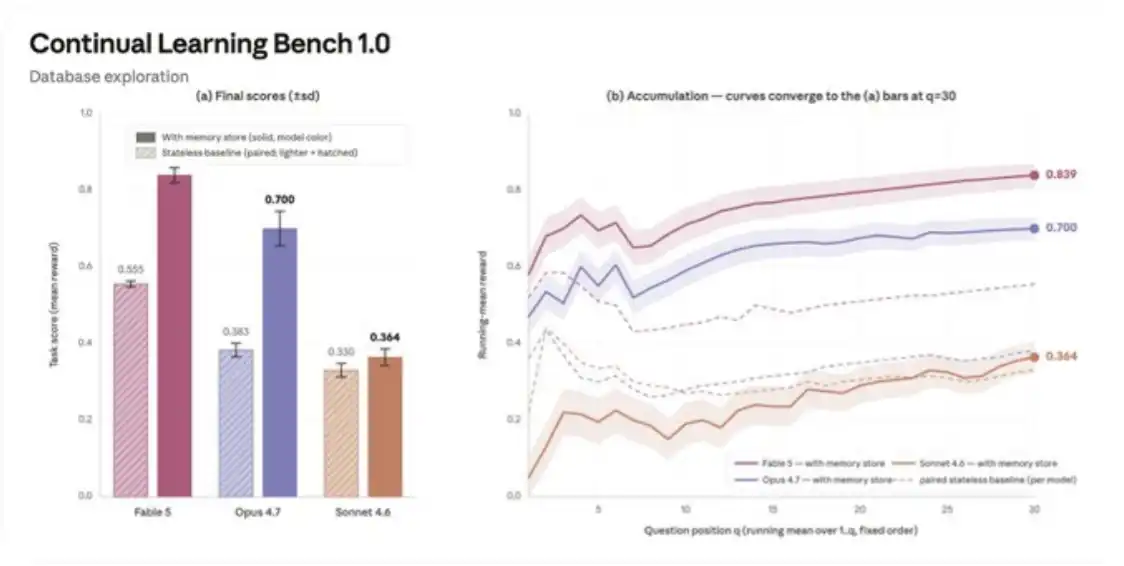
我在这个基准测试中的一项任务上,对比了 Fable 5、Opus 4.7 和 Sonnet 4.6。这个任务要求 Agent 在访问一个 SQL 数据库的前提下,连续回答一系列问题。每个问题都是一次独立的 Agent 会话,并且会提供记忆能力。
为此,我使用了带有记忆功能的 CMA。它会为每个 Agent 提供一个挂载的文件系统,并且这个文件系统可以在不同会话之间共享。
对于这项任务来说,想要有效利用记忆,通常需要经历这样一个递进过程:失败(答错并记录下来)、调查(在继续之前弄清楚错因)、验证(把诊断结果变成经过检查的事实)、提炼(把验证结果转化为通用规则),以及查阅(之后直接读取规则,而不是重新推导一遍)。
Sonnet 4.6 大约停留在第 1 步:它的记忆存储更像是一串失败笔记和未定猜测,比如「也许应该用 prc,而不是 prc_usd?」它很少查阅此前的笔记。若想提升表现,就需要加入面向具体任务的记忆使用说明。
Opus 4.7 大约推进到第 3 步:它会创建一份 schema 参考文档,并标注其中的不确定性,比如「prc 可能是以美分计价?需要验证。」但它的验证覆盖率并不高:只覆盖了 7% 到 33% 的问题,中位数运行结果约为 17%。
Fable 5 则倾向于完成整个递进过程:在表现最好的几次运行中,它的验证覆盖率最高达到 73%,也就是 30 个问题中验证了 22 个,并且会把学到的内容提炼成通用规则,从而帮助后续任务。
因此,与其直接提示并不断引导 Fable 5,很多时候更好的方式,是设计一套循环,让模型能够根据环境反馈自我纠错,比如使用 /goal 或 Outcomes;同时让它自己管理上下文,比如通过记忆机制来完成。
我这里只分享了几个自己做过的小规模实验,但 Fable 5 很值得你亲自在高难度任务上测试,尤其是结合自我纠错循环或记忆机制来使用。
想要上手,可以查看我们的文档,或者直接询问最新版 Claude Code。它可以使用内置的 /claude-api skill,向你介绍 Fable 5,比如 Prompt 最佳实践、/goal、Claude Managed Agents,或其他 API 功能。
[原文链接]