4-17%. This is the prompt cache hit rate for Claude Code in the past month. The normal level is 97-99%.
This means that when you resume a previous session, Claude Code does not reuse the previously processed context, but instead processes everything from scratch each time, consuming credits at a rate 10 to 20 times higher than normal. You may think you are continuing a conversation, but in reality, you are starting a completely new, full-priced conversation each time.
This data comes from independent developer ArkNill's proxy monitoring. By setting up a transparent proxy, he recorded every request between Claude Code and the Anthropic API, uncovering at least two client-side caching bugs that caused the API server to be unable to match cached conversation prefixes, forcing a full token rebuild each round.
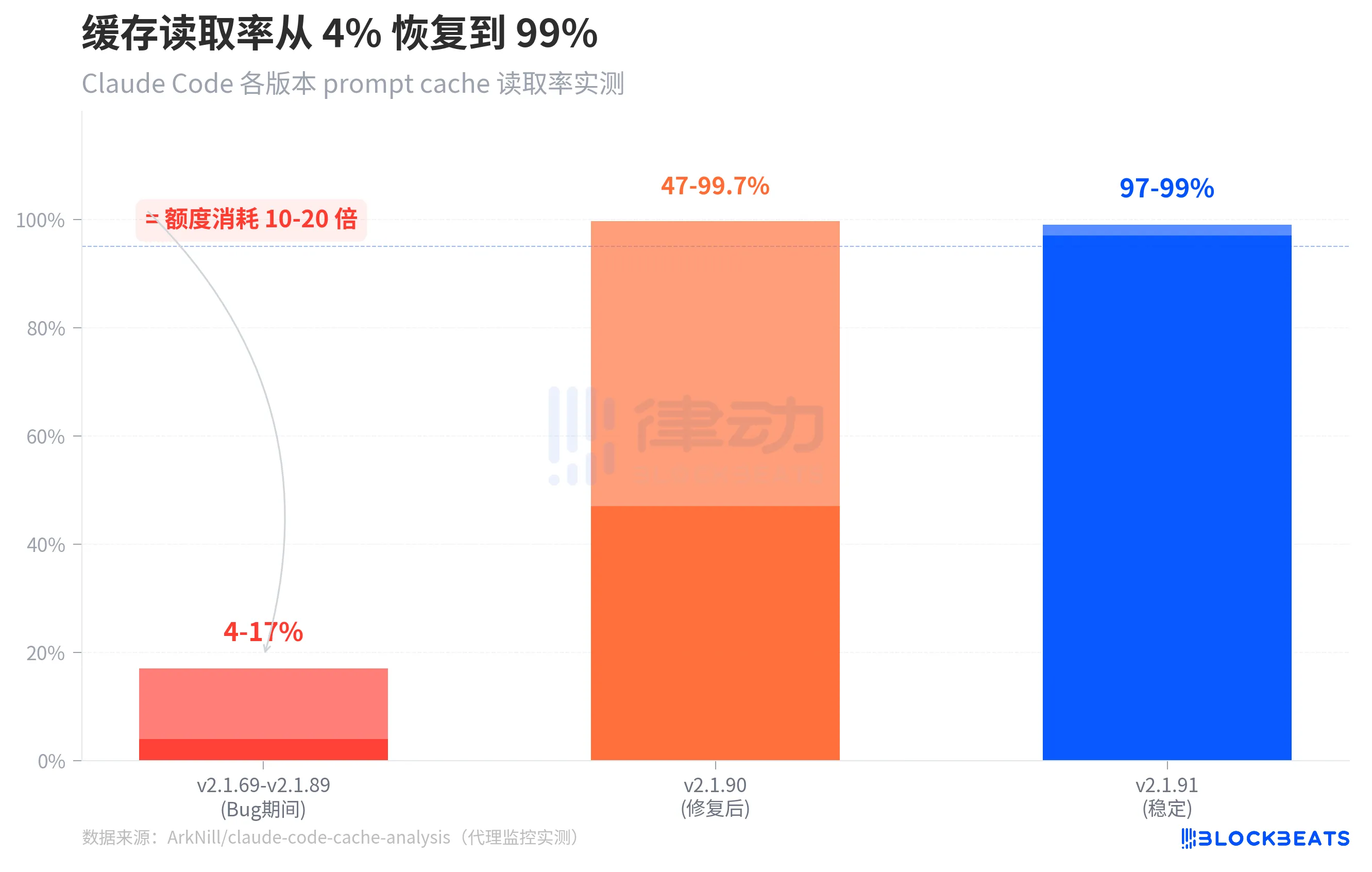
The graph above shows a comparison of cache hit rates across three stages. During versions v2.1.69 to v2.1.89 (the period of the bug), the standalone version's cache hit rate was only 4-17%. After fixing a critical bug in version v2.1.90, the cold start cache hit rate returned to 47-99.7%. By v2.1.91, the stable cache hit rate recovered to 97-99%.
One notable detail from the chart: the range in v2.1.90 is quite wide (47% to 99.7%) because the cache still needs to "warm up" when a session is just resumed, resulting in low hit rates in the first few rounds, but quickly returning to normal. In the bugged version, this warm-up never occurs — the cache hit rate always stays at 14,500 tokens of system prompt, with the full conversation history being fully billed each time.
28 Days, 20 Versions
This bug is not the type introduced in one update and fixed in the next. According to the npm registry release records, the version v2.1.69 that introduced the bug was released on March 4, and the version v2.1.90 that fixed the bug was released on April 1. There were 28 days in between, spanning 20 versions.
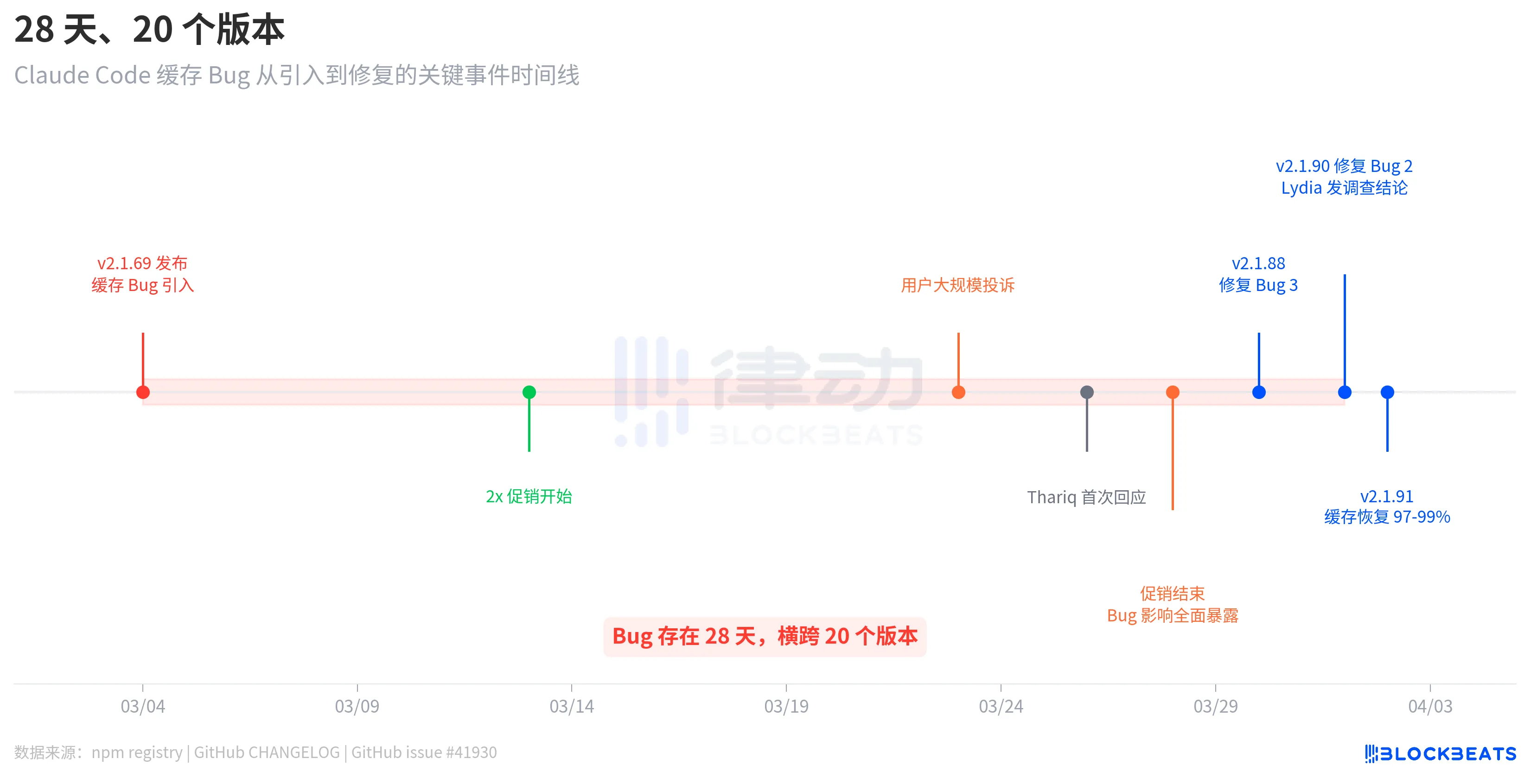
The timeline revealed a tantalizing detail. After the bug was introduced on March 4, users did not immediately complain on a large scale. It wasn't until March 23 that the complaints erupted en masse, almost three weeks later. The reason is that, according to the GitHub issue #41930 analysis, from March 13 to 28, Anthropic had a 2x quota promotion live (doubling during off-peak hours), which objectively masked the impact of the bug. After the promotion ended, the cache bug consumption returned to normal billing baselines, and users' quotas instantly "evaporated."
Anthropic's response was not swift. On March 26, three days after the user complaints erupted, engineer Thariq Shihipar announced on his personal X account that the peak hour limit (weekdays 5am-11am PT) had been tightened. On March 30, Anthropic admitted on Reddit that the "rate at which users hit their quota far exceeded expectations," listing it as the team's top priority. It wasn't until April 1 that team member Lydia Hallie released the official investigation findings.
Throughout the process, Anthropic did not release any blog posts, send email notifications, or update the status page. All official communication was done solely through engineers' personal social media posts and a few Reddit comments.
How Much Did You Pay, and How Long Can You Use It?
GitHub issue #41930 collected hundreds of user reports. The most extreme case was a Max 20x subscription user ($200/month), whose 5-hour rolling window was entirely consumed in 19 minutes. Max 5x users ($100/month) reported their 5-hour window was used up in 90 minutes. According to The Letter Two, some users claimed that a simple "hello" consumed 13% of their session quota. A Pro user ($20/month) on Discord mentioned that his quota "ran out every Monday and only reset on Saturday," with only 12 days of normal usage in 30 days.

Based on ArkNill's benchmark testing, in bug version v2.1.89, the 100% quota of the Max 20x plan would be depleted in about 70 minutes. He also calculated the cost of a single --resume operation for a 500K token context session, which is approximately $0.15, as the system fully replays the entire context.
「You're Holding It Wrong」
Lydia Hallie's investigation confirmed two points: first, there has indeed been a tightening of peak-hour limits, and second, there has been an increase in token consumption within the 1 million token context. She mentioned that the team fixed some bugs but emphasized that "none of the bugs led to overcharging."
She then provided four frugality recommendations:
1. Use Sonnet 4.6 instead of Opus (Opus consumes at about twice the rate);
2. Lower the reasoning depth or turn off extended thinking when deep reasoning is not needed;
3. Do not resume long idle sessions for over an hour; start a new one instead;
4. Set the environment variable CLAUDE_CODE_AUTO_COMPACT_WINDOW=200000 to limit the context window size.
No mention was made of any form of quota reset or compensation.
AI podcast host Alex Volkov summarized this response as "You're holding it wrong," pointing out that Anthropic itself set the 1 million token context as the default, promoted Opus as the flagship model, and highlighted extended thinking as a selling point, but is now advising paying users not to use these features.
The assertion of "no overcharging" also creates tension with Claude Code's own update history. Just the day before Lydia's response, v2.1.90 fixed a cache regression bug that had been present since v2.1.69: when using --resume to resume a session, requests that should have hit the cache would trigger a complete prompt cache miss, resulting in full billing. Lydia's response did not mention this confirmed billing anomaly.

For comparison, OpenAI's Codex had previously experienced similar abnormal quota consumption issues. OpenAI's approach was to reset user quotas, issue credit refunds, and announce the removal of the usage cap on Codex in March. Anthropic's approach is to advise users to downgrade models, disable features, limit context, and attribute responsibility to user usage.
Anthropic sells a subscription for the "strongest model + maximum context + highest reasoning capabilities," charging a fee of $20 to $200 per month. A 28-day caching bug caused the paid users' quotas to deplete at a rate 10-20 times faster, with the official response being to use it sparingly.