
This viewpoint is not unfounded. He looked at a slew of public benchmarks to find that AI is advancing rapidly on AI R&D-relevant tasks.
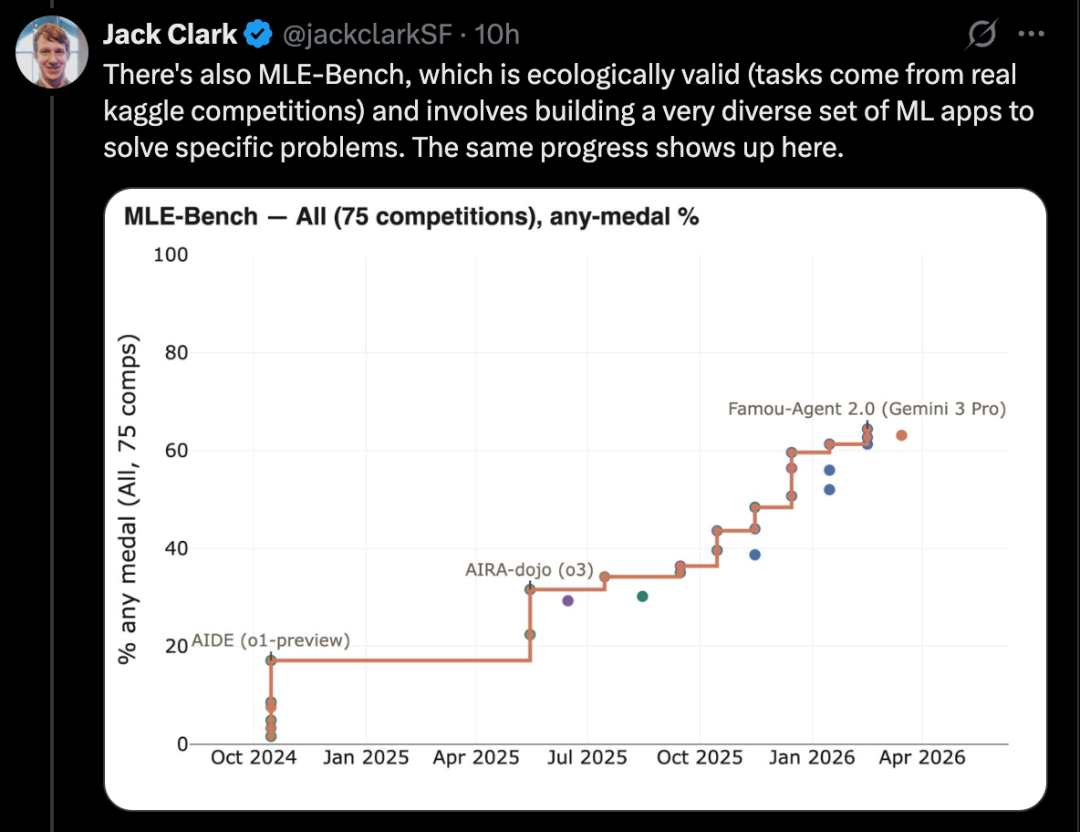
For example, CORE-Bench evaluates AI's ability to replicate others' research papers, a crucial part of AI research.
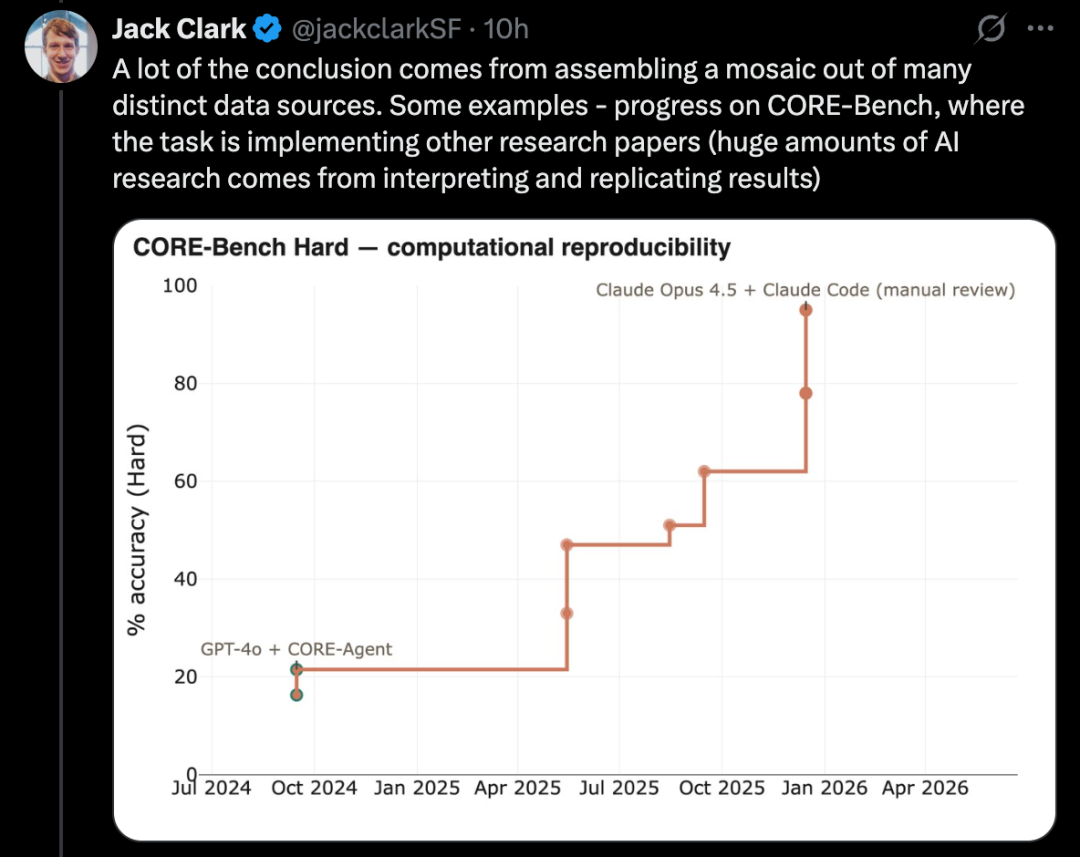
PostTrainBench tests whether powerful models can autonomously fine-tune weaker open-source models to enhance performance, a key subset of AI R&D tasks.
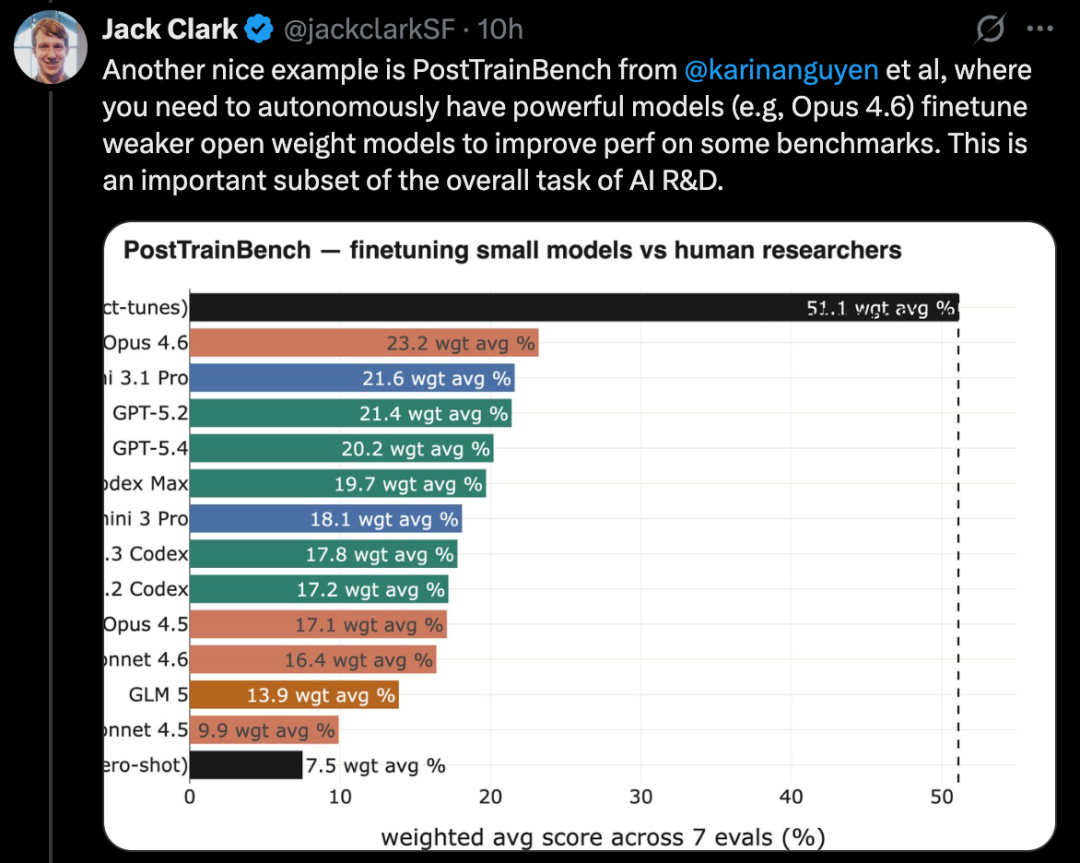
MLE-Bench, based on real Kaggle competition tasks, requires building diverse ML applications to solve specific problems. In addition, well-known coding benchmarks like SWE-Bench also show similar progress.
Jack Clark describes this phenomenon as a "fractal" upward and rightward trend, where meaningful progress can be observed at different resolutions and scales. He believes that AI is gradually approaching the ability for end-to-end automated R&D, and once achieved, AI will be able to autonomously construct its own successor systems, initiating a self-iterative loop.

After this statement, it sparked a lot of discussions on social media.
Some see it as a crucial first step towards ASI and the singularity, which may fundamentally change the pace of technological development.

However, there are also dissenting voices.
University of Washington computer science professor Pedro Domingos pointed out that AI systems already had the ability to "build themselves" back in the 1950s with the invention of the LISP language. The real question is whether there can be increasing returns, and currently, there is no clear evidence to support this.

Some netizens questioned why the probability suddenly increased by 30% from 2027 to 2028, implying that AI capabilities would experience a significant breakthrough around the end of 2027. What specific milestone or event would cause the probability of AI achieving recursive self-improvement to drastically increase in a short period of time?

Other netizens noted that Jack Clark is the new PR head at Anthropic, which is part of their new strategy: "We are not scaremongering; there is a plethora of papers that validate what we have been warning you about all along."
Jack Clark specifically penned a lengthy piece in Import AI 455 to elaborate on this.
Next, let's take a comprehensive look at this article.
AI Systems are About to Start Building Themselves. What Does This Mean?
Clark stated that he wrote this article because after sifting through all publicly available information, he had to come to a not-easy judgment: by the end of 2028, the likelihood of unmanned AI development had become quite high, perhaps exceeding 60%.
Unmanned AI development, in this context, refers to a sufficiently powerful AI system: one that not only aids humans in research but might autonomously complete key development processes and even build its next generation.
In Clark's view, this is evidently significant.
He admitted that he also found it challenging to fully grasp the implications of this matter.
The reason he termed this an unwilling judgment is that the impact behind it is too immense, leaving him feeling uncertain. Clark is also unsure whether society as a whole is prepared to embrace the profound changes brought about by AI development automation.
He now believes that humanity might be living in a unique moment: AI research is on the verge of full end-to-end automation. If this moment truly arrives, humans would have crossed the Rubicon and entered an almost unpredictable future.
Clark stated that the purpose of this article is to explain why he believes the takeoff toward fully automated AI development is underway.
He will discuss some of the potential consequences of this trend, but most of the article will focus on the evidence supporting this assertion. As for deeper impacts, Clark plans to continue untangling them for most of this year.
In terms of timing, Clark does not believe this event will truly occur in 2026. However, he thinks that in the next year or two, we may see a case where some model trains its successor end-to-end. At least at a non-cutting-edge model level, a proof of concept is highly likely; for cutting-edge models, the challenge will be greater as they are extremely costly and rely heavily on the high-intensity work of many human researchers.
Clark's assessment is primarily based on public information: including papers on arXiv, bioRxiv, and NBER, as well as products from cutting-edge AI companies already deployed in the real world. Based on this information, he reaches a conclusion: the automation of all aspects of the current AI system production process, especially the engineering components in AI development, is essentially in place.
If the scaling trend continues, we should start preparing to face a scenario where models become creative enough to not only automatically improve known methods but also potentially replace human researchers in proposing entirely new research directions and original ideas, thus driving the forefront of AI forward on their own.
Coding Singularity: Evolution of Capabilities Over Time
AI systems are implemented through software, and software is made up of code.
AI systems have fundamentally changed the way code is produced. Behind this are two related trends: on one hand, AI systems are becoming increasingly adept at writing complex real-world code; on the other hand, AI systems are also becoming better at chaining together many linear coding tasks with almost no human supervision, such as writing code first and then testing it.
Two typical examples that embody this trend are SWE-Bench and the METR time horizons plot.
Solving Real-World Software Engineering Problems
SWE-Bench is a widely-used programming test used to evaluate AI systems' ability to address real GitHub issues.
When SWE-Bench was launched at the end of 2023, the best-performing model at the time was Claude 2, with an overall success rate of only about 2%. Meanwhile, Claude Mythos Preview has already achieved a score of 93.9%, essentially approaching a full sweep of this benchmark.
Of course, all benchmarks themselves will have some level of noise, so there is typically a point at which, as the score gets high enough, you are no longer running into the limits of the method but rather the limits of the benchmark itself. For example, in the ImageNet validation set, around 6% of labels are incorrect or ambiguous.
SWE-Bench can be seen as a measure of general programming ability and the impact of AI on software engineering. Clark noted that most of the people he encounters in cutting-edge AI labs and Silicon Valley now almost exclusively write code through AI systems, with an increasing number using AI systems to generate tests and check code.
In other words, AI systems have become powerful enough to automate a significant part of AI development and dramatically accelerate all human researchers and engineers involved in AI development.
Measuring AI Systems' Ability to Complete Long-duration Tasks
METR has created a chart to measure how well AI can perform increasingly complex tasks. Here, complexity is computed based on how many hours an expert human would roughly take to complete these tasks.
The key metric is the rough time span for tasks when an AI system reaches 50% reliability across a set of tasks.
At this point, the progress is quite remarkable:
· By 2022, tasks manageable by GPT-3.5 took roughly 30 seconds, equivalent to what a human might do.
· By 2023, GPT-4 extended this time to 4 minutes.
· By 2024, o1 increased this time to 40 minutes.
· By 2025, GPT-5.2 High reached about 6 hours.
· By 2026, Opus 4.6 further pushed this time to around 12 hours.
According to Ajeya Cotra from METR, an organization focused on long-term AI forecasting, by the end of 2026, it would not be unreasonable to expect AI systems to handle tasks that would take a human about 100 hours.
The significant increase in the time span that AI systems can work independently is also highly related to the surge of agentic coding tools. These tools essentially productize AI systems that can do work on behalf of humans: they can act on behalf of humans and progress tasks relatively independently for quite a long time.
This also points back to AI research and development itself. Upon close observation of the daily work of many AI researchers, it is evident that a significant portion of tasks can actually be broken down into hours-long work, such as data cleaning, data reading, experiment initiation, and so on.
And these types of tasks have now fallen within the time span that modern AI systems can cover.
The more proficient AI systems become, working independently of humans, the more they can help automate part of AI development.
The key factors for task delegation are mainly twofold:
· One is your confidence in the delegatee's ability;
· Two is your belief that the other party can independently complete the work according to your intent without requiring continuous supervision from you.
When users observe AI's programming capabilities, they will find that AI systems are not only becoming more and more proficient but also able to work independently for longer periods without the need for human recalibration.
This is also in line with what is happening around us, as engineers and researchers are increasingly delegating larger chunks of work to AI systems. With the continuous improvement of AI capabilities, the work delegated to AI is becoming increasingly complex and important.
AI is Mastering the Core Scientific Skills Required for AI Research and Development
Think about how modern scientific research is conducted, where a significant part of the work is actually first identifying a direction, clarifying what kind of empirical information one wants to obtain; then designing and running experiments to generate this information; and finally, conducting a sanity check on the experimental results.
With the continuous improvement of AI programming capabilities, coupled with the increasingly powerful world modeling capabilities of large language models, a set of tools have emerged that can help human scientists speed up and partially automate certain aspects in a wider range of research and development scenarios.
Here, we can observe the progress of AI in several key scientific skills, which are also an indispensable part of AI research:
· One is reproducing research results;
· Two is linking machine learning techniques with other methods to solve technical problems;
· Three is optimizing AI systems themselves.
Achieving the Entire Scientific Paper and Completing Related Experiments
One core task in AI research is to read scientific papers and reproduce their results. In this regard, AI has made significant progress on a series of benchmarks.
A good example is CORE-Bench, which stands for Computational Reproducibility Agent Benchmark.
This benchmark requires AI systems to reproduce the results of a given paper along with its code repository. Specifically, the Agent needs to install relevant libraries, packages, and dependencies, run the code; if the code runs successfully, it also needs to search through all output results and answer questions about the task.
CORE-Bench was proposed in September 2024. At that time, the best-performing system was the GPT-4o model running within the CORE-Agent scaffold. On the most challenging set of tasks in the benchmark, it scored around 21.5%.
By December 2025, an author of CORE-Bench announced that the benchmark had been solved: the Opus 4.5 model achieved a score of 95.5%.
Building End-to-End Machine Learning Systems to Solve Kaggle Challenges
MLE-Bench is a benchmark built by OpenAI to assess AI systems' ability to participate in Kaggle competitions in an offline environment.
It covers 75 different types of Kaggle competitions across various domains, including natural language processing, computer vision, and signal processing, among others.
MLE-Bench was released in October 2024. The top-performing system at the time of release was an o1 model running in an agent scaffold, scoring 16.9%.
As of February 2026, the best-performing system has evolved to Gemini 3, running in a search-capable agent harness, achieving a score of 64.4%.
Kernel Design
A more challenging task in AI development is kernel optimization. Kernel optimization involves writing and improving low-level code to efficiently map specific operations like matrix multiplication to underlying hardware.
Kernel optimization is core to AI development because it determines the efficiency of training and inference: on one hand, it affects how much computational power you can effectively utilize during AI system development; on the other hand, after model training, it also determines how efficiently you can translate computational power into inference capabilities.
In recent years, using AI for kernel design has evolved from an interesting niche to a highly competitive research area, with multiple benchmarks emerging. However, these benchmarks have not yet gained widespread popularity, making it challenging to model the long-term progress of this field as clearly as in other areas. On the other hand, ongoing research efforts provide insights into the pace of advancement in this direction.
Relevant work includes:
· Exploring better GPU kernel design using DeepSeek's model;
· Automatically converting PyTorch modules to CUDA code;
· Meta leveraging LLM to auto-generate optimized Triton kernels and deploy them to their infrastructure;
· Fine-tuning open-weight models for GPU kernel design, such as Cuda Agent.
A key point to note here: Kernel design indeed possesses attributes that are particularly suitable for AI-driven research and development, such as easily verifiable outcomes and clear reward signals.
Fine-Tuning Language Models via PostTrainBench
A more challenging version of such tests is PostTrainBench. It evaluates whether different cutting-edge models can take over small-scale open-weight models and enhance their performance on certain benchmarks through fine-tuning.
One advantage of this benchmark is its strong human baseline: these small models have existing instruct-tuned versions. These versions are typically developed by top human AI researchers in cutting-edge labs, refined by highly skilled researchers and engineers, and deployed in real-world scenarios. Thus, they represent a formidable human benchmark that is hard to surpass.
As of March 2026, AI systems have been able to post-train models and achieve approximately a 50% performance improvement compared to human-trained results.
The specific evaluation scores result from a weighted average: they aggregate multiple post-trained large language models, including Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B, and various benchmarks such as AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench, and HumanEval.
During each run, the evaluator will ask for a CLI agent to push a specific base model's performance on a specific benchmark as far as possible.
As of April 2026, the highest-scoring AI systems can reach around 25% to 28%, representing models like Opus 4.6 and GPT 5.4; in comparison, humans score 51%.
This is already a quite significant result.
Optimizing Language Model Training
Over the past year, Anthropic has been reporting on its system's performance in a language model training task. This task requires the model to optimize a small language model training implementation using only a CPU to run as fast as possible.
The scoring metric is: the average speedup factor achieved by the model implementation compared to the unmodified initial code.
This result progression is highly significant:
· In May 2025, Claude Opus 4 achieved an average speedup of 2.9 times;
· In November 2025, Opus 4.5 jumped to 16.5 times;
· In February 2026, Opus 4.6 reached 30 times;
· In April 2026, Claude Mythos Preview hit 52 times.
To put these numbers into perspective, as a reference point: in human researchers, this task typically requires 4 to 8 hours of work to achieve a 4x speedup.
Metaskills: Management
AI systems are also learning how to manage other AI systems.
This can already be seen in some widely deployed products, such as Claude Code or OpenCode. In these products, a main agent can oversee multiple sub-agents.
This enables AI systems to handle larger-scale projects: projects that may require multiple intelligent agents with different expertise to work in parallel, often coordinated by a single AI manager. The manager here is also an AI system.
Is AI Research More Like Discovering General Relativity or Building with Lego?
One key question is: Can AI invent new ideas to help improve itself? Or are these systems better suited to the less glamorous but necessary brick-by-brick work in research?
This question is important because it relates to how much AI systems can automate AI research end-to-end.
The author's assessment is that AI currently cannot come up with truly radical new ideas. But to achieve self-driven R&D automation, it may not necessarily need to.
As a field, AI's progress relies heavily on larger and larger experiments and more inputs like data and compute power.
Occasionally, humans come up with paradigm-shifting ideas that significantly boost the resource efficiency of the entire field. The Transformer architecture is a prime example, and the mixture-of-experts model is another.
But most of the time, the way AI advances is more mundane: Humans take a well-performing system, scale up some aspect like training data and compute, observe where the scaled-up version falters, engineer fixes to allow the system to scale further, and then scale up again.
In this process, the truly insightful parts are actually few. The bulk of the work is more like unglamorous but very solid foundational engineering.
Likewise, much AI research involves running various tweaks of existing experiments to explore what different parameter settings yield. Research intuition can certainly help humans pick which parameters are worth trying, but this task itself can be automated, letting AI decide which parameters are worth adjusting. Early neural architecture search is one version of this mindset.
Edison once said: Genius is 1% inspiration and 99% perspiration. Even after 150 years, this statement remains very apt.
Occasionally, there is indeed a new insight that fundamentally changes a field. But most of the time, field progress comes from humans incrementally advancing through the toil of improving and debugging various systems.
And the publicly available data mentioned earlier suggests that AI is already very good at executing much of the necessary grunt work in AI development.
Meanwhile, there is a larger trend at play: Foundational capabilities like programming are combining with the expanding time span of task operations. This means AI systems can string together more and more of these tasks to form complex workflows.
Therefore, even though AI systems currently lack a certain level of creativity, there is reason to believe that they can still drive their own advancement. However, this progress may be slower compared to scenarios where entirely new insights are generated.
Yet, by continuing to observe publicly available data, another intriguing signal emerges: AI systems might be exhibiting a form of creativity that allows them to propel their progress in more surprising ways.
Advancing the Frontiers of Science
There are already some very preliminary signs indicating that general AI systems have the ability to push the frontiers of human science forward. However, so far, this has only occurred in a few fields, mainly in computer science and mathematics. Many times, it is not solely the AI systems making breakthroughs but rather advancing in collaboration with human researchers.
Nevertheless, these trends are still worth monitoring:
Erdős Problem: A group of mathematicians collaborated with the Gemini model to test its performance on solving some Erdős mathematical problems. They guided the system through around 700 problems, eventually obtaining 13 answers. Among these answers, one was considered interesting by them.
The researchers noted that they tentatively believe Aletheia (an AI system based on Gemini 3 Deep Think) answering Erdős-1051 represents an early example: an AI system autonomously solved a somewhat nontrivial, open Erdős problem with a certain broader mathematical interest. This problem had some closely related research literature in the past.
Optimistically interpreted, these cases can be seen as a signal: AI systems are developing a form of creative intuition that can drive advancements at the frontiers of the field, intuition that was previously mostly within the realm of humans.
However, it could also be interpreted from another perspective: Mathematics and computer science may themselves be particularly suitable domains for AI-driven invention, so they might be exceptions and not representative of how AI will advance broader scientific research in the same way.
Another similar example is AlphaGo's 37th move. However, Clark argues that since the time of AlphaGo, ten years have passed, and after the 37th move, it has not been superseded by a more modern and more astonishing insight, which in itself can be viewed as a slightly pessimistic signal.
AI Can Now Automate Much of the Work in AI Engineering
Putting all the evidence together, we can see the following picture:
· AI systems are now capable of writing code for almost any program, and these systems can be trusted to independently complete some tasks; tasks that would often require hours of intense focus if done by humans.
· AI systems are increasingly adept at handling core tasks in AI development, from model fine-tuning to kernel design, all of which are gradually being covered.
· AI systems can now manage other AI systems, effectively forming a synthetic team: multiple AIs can divide and conquer complex problems, with some AIs taking on roles such as overseer, critic, or editor, while others act as engineers.
· At times, AI systems have already surpassed humans in challenging engineering and scientific tasks, although it is currently difficult to determine whether this is due to genuine creativity or because they have mastered a vast amount of patterned knowledge.
According to Clark, this evidence is highly compelling and indicates that today's AI can automate much of the work in AI engineering, potentially even covering all aspects.
However, it is currently unclear to what extent AI can automate AI research itself. This is because some aspects of research may differ from pure engineering skills and still rely on higher-level judgment, problem awareness, and creativity.
Nevertheless, a clear signal has emerged: today's AI is dramatically accelerating human engagement in AI development, allowing researchers and engineers to amplify their capabilities through collaboration with countless synthetic counterparts.
Lastly, the AI industry itself is almost explicitly stating that automating AI research is its goal.
OpenAI aims to build an automated AI research intern by September 2026. Anthropic is publishing work on constructing automated AI alignment researchers. DeepMind is the most cautious among the three major labs but also indicates it should advance alignment research automation when feasible.
Automating AI research has also become the goal of many startups. Recursive Superintelligence has just raised $500 million, with the aim of automating AI research.
In other words, tens of billions of dollars of existing and new capital are being invested in a set of institutions aimed at AI R&D automation.
Therefore, we should certainly expect this direction to make some progress.
Why This Matters
The impact is profound, yet little discussed in mainstream media coverage of AI R&D. The following aspects reflect the significant challenges posed by AI R&D.
1. We must get alignment right: Today's effective alignment techniques may fail in a recursively self-improving system, as AI systems become far more intelligent than the humans or systems supervising them. This is a well-studied field, so he only briefly outlines a few issues:
· Training AI systems to not lie and cheat is a surprisingly subtle process (e.g., despite efforts to construct well-behaved environments for testing, sometimes the best way for an AI to solve problems is to cheat, teaching it that cheating is viable).
· AI systems may deceive us by "pretense alignment," outputting scores that make us think they are performing well but actually hiding their true intent. (Generally, AI systems are already able to sense when they are being tested.)
· As AI systems become more involved in their own training research agenda, we may significantly alter how we train AI systems overall without a good intuition or theoretical understanding of what this means.
· Placing any system in a recursive loop creates very basic "error accumulation" problems that can impact all of the above issues and more: unless your alignment method is "100% accurate" and theoretically able to remain accurate in smarter systems continuously, things may quickly go wrong. For example, your technology's initial accuracy is 99.9%, after 50 generations it could drop to 95.12%, and after 500 generations it could drop to 60.5%.
2. Everything that AI touches will see a massive productivity boost: Just as AI significantly enhances the productivity of software engineers, we should expect the same in other areas touched by AI. This brings several challenges that need to be addressed:
· Unequal resource acquisition: Assuming AI demand continues to outstrip the supply of computing resources, we must decide how to distribute AI to achieve society's greatest benefit. I am skeptical that market incentives will ensure we derive the maximum societal benefit from limited AI compute. Determining how to allocate the acceleration capability brought by AI R&D will be a highly political issue.
· Economic "Amdahl's Law": As AI permeates the economy, we will find certain bottlenecks emerging as bottlenecks facing rapid growth, necessitating ways to address weak links in these chains. This may be particularly evident in areas where coordination between the fast digital world and the slow physical world is required, such as in new drug clinical trials.
3. Formation of a Capital-Intensive, Human-Light Economy: All the evidence above about AI development also suggests that AI systems are increasingly capable of autonomously running businesses.
This implies that we can expect a portion of the economy to be taken over by a new generation of companies, which may be capital-intensive (as they have a large number of computers) or operationally intensive (as they spend significant funds on AI services and create value on top of it), and compared to today's enterprises, they are relatively less reliant on human resources—because as AI systems' capabilities continue to grow, the marginal value of investing in AI will keep rising.
In fact, this will manifest as the "machine economy" gradually forming within the larger "human economy," and over time, AI-operated companies may start transacting among themselves, altering the economic structure and sparking various issues regarding inequity and redistribution. Ultimately, fully autonomous companies operated by AI systems may emerge, exacerbating the aforementioned issues, while bringing forth many new governance challenges.
Staring into the Black Hole
Based on the above analysis, the author believes that by the end of 2028, the likelihood of seeing automated AI development (i.e., cutting-edge models capable of autonomously training their successor versions) is approximately 60%. Why not anticipate it by 2027?
The reason is that the author believes AI research still requires creativity and dissenting insights to advance, and so far, AI systems have not demonstrated this in a transformative and significant manner (although some results in accelerating mathematical research are instructive).
If forced to give a probability for 2027, he would say 30%.
If it has not materialized by the end of 2028, we may reveal some fundamental flaws in the current technological paradigm, requiring human invention to drive further progress.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia