Editor's Note: The "sloppiness" in AI-generated content is often attributed to weak prompts, inadequate models, or incomplete context. However, this article proposes a more engineering-system-like assessment: the problem lies not on the input side but on the output side.
The author believes that many have tried repeatedly to rewrite prompts, upgrade models, enable memory, and stack context files, yet AI slop continues to occur. The reason is that these methods focus on optimizing the "generation" itself without establishing a stable quality control mechanism. Just as a factory would not rely solely on a worker's intuition to determine if a product should be shipped, AI output should not flow directly from the model to the user without testing, scoring, and interception.
The core solution proposed in the article is to build an eval loop in the open-source Agent called Hermes: first, define what constitutes "good output," then translate that standard into a quantifiable scoring system, and continuously monitor before release, at runtime, and in production environments. Whether it's hollow expressions in content creation or illusionary answers, formatting errors, and degraded experiences in products, fundamentally, unmeasured AI output reaches the audience directly.
Therefore, the key is not to create a longer prompt but to add a missing layer of a quality system. Test cases, scoring metrics, thresholds, regression testing, approval buttons, and production environment monitoring together form this mechanism. It transforms "AI output quality" from a subjective feeling into a set of observable, comparable, and repairable metrics.
The following is the original text:
Some seem to consistently deliver top-notch software, write compelling content, or generate stunning images, and there's a reason behind it.
They have an eval loop, and you don't.
You've tried better prompts, more expensive models, longer commands, activated memory, and built massive context files like a novel, but AI garbage content still surfaces.
It persists because you've been trying to patch up a layer that was never broken in the first place.
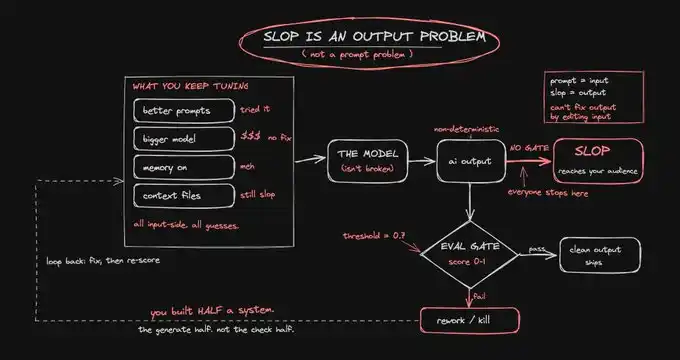
AI garbage content is not a prompt issue; it's a systemic issue. Just like a factory continuously producing defective products, the problem is not with a specific worker but with the quality control mechanism: no one is checking the product before it leaves the building.
So, the goal of this article is to establish this mechanism. By the end of it, you will have an eval loop that can run in the Hermes open-source Agent: it will score each output against your criteria before each release, continue to monitor real-world performance post-release, and turn every failure into a new test to automatically raise the quality bar.
We will build this step by step. The ultimate benefit is specific: you can achieve truly clean, trustworthy output without having to painstakingly recheck every word in the middle of the night; you will have a visible quality score; AI garbage content will be intercepted before it leaves the door, rather than waiting for your audience to discover it.
You will take away the following from this article:
Why better prompts, larger models, and memory capabilities can never completely eliminate AI garbage content, and which layer truly makes a difference;
AI garbage content lurks in two places in your work: content output and product output; and why the approach to fixing both is actually exactly the same;
Explaining in plain terms what an eval loop is: a quality layer that few people run daily, and why no one has ever reminded you to build it;
A quality baseline that can be set up this week, applicable to both content and product: what specific metrics to measure, and which number on the screen qualifies as "good";
A complete set of building steps: how to use the components already provided by Hermes—skills, memory, cron, and approval buttons—to string the entire loop together, allowing the quality gate to run automatically without relying on your manual oversight.
If you came here for the "5 phrases to combat AI garbage content," this is not it.
Such things do exist, but they are not truly effective. This article discusses the effective version.
You've tried almost everything except the one thing you really should.
First, let's briefly review what you have already done: you've rewritten prompts three, four times; you've added examples, personas, and a long list of "don'ts." You've upgraded to cutting-edge models, spent five times more on each token, and the output has only become more confident but not less empty. You've activated memory, built contextual files, and fed it your brand's voice, past works, and style guide.
Each of these operations will give you several good generations. Then, AI-generated junk content will slowly creep back in.
Because all of this is a patch on the input side. You've been polishing that 'generation' thing all along, ignoring what you should really be responsible for 'interception'. No matter how good the gun is, if you're just firing into the darkness, you still won't hit anything.
AI junk content is an output-side issue. The problem is not that the model cannot produce good work, but that you cannot pre-determine which are good and bad works before they reach important people.
You don't have an eval loop, quality benchmark, or a scoreboard. So you've been tuning blindly. You change a prompt word, feel like it's getting better, but feelings are not measurements, and feelings cannot stop the lousy output hidden in the next 50 generations.
So you start blaming yourself, blaming the prompt words, blaming the agent setup, blaming the context engineering. But what is really missing is a whole layer of AI workflow that you have never been taught. And after reading this article, this layer will run on your machine and in Hermes.
Why Better Prompt Words Won't Solve This Problem and Why Everyone Keeps Trying
Prompt words are an assumption, output is a result, and eval is the only thing that can close the loop between the two.
Without this loop, you will always be stuck in speculation. You adjust the assumption, visually see one result, and then declare victory. You will never realize that the same prompt word actually produces junk 30% of the time because you only look at the current output each time.
The model is non-deterministic. Running the same prompt word twice will give two different answers. This means that even with a 'perfect' prompt word, a certain percentage of runs will generate AI junk content. And you won't know which one it is before the customer or user actually sees it.
So, a perfect prompt word is not a quality guarantee; it's just a slightly higher chance of winning a coin flip. And you are now sending out the results of every coin flip directly.
The reason why everyone keeps hoping for prompt words is simple: prompt words are the only visible leverage you have. You can edit it, and editing it gives you a sense of control.
Measurement, on the other hand, is invisible. No one sells you a course on measurement, and no one will post a viral post titled 'This eval suite has improved my output quality tenfold.' So, the whole discussion is stuck on the lever that cannot solve the problem when used alone.
Those AI outputs that always look clean aren't better at writing prompts than you. They just have one leverage you don't: they measure each output against a set of standards before publishing it. It's this measuring mechanism that makes their prompts look like magic.
AI Trash Content Hides in Two Places
AI trash content only hides in two places, and almost everyone only focuses on one of them.
The first place is your content output.
Tweets, articles, emails, landing pages, posts—anything you generate with AI and publish under your name falls into this category.
The AI trash content here often appears as work that is "technically correct but totally hollow." It sounds like everything every AI account has ever put out on a timeline: outwardly right but inwardly empty.
It fails in public, and you can't quite put your finger on why because each piece looks okay on its own when you hit send.
The second place is your product output.
The AI features you launch, agents, chatbots, customer service responders, information extraction pipelines—anything the user actually interacts with falls into this category.
The AI trash content here may manifest as a confidently wrong answer, a hallucinated number, a broken JSON output, a tone that doesn't match the brand, or an output that performed well in demos but quietly degraded after three deployments.
It doesn't die immediately in public. It spreads silently. Every user gets a slightly worse experience, and most will never tell you. They'll just leave.
Both of these are the same disease, and the solution is also the same.
Content trash and product trash are fundamentally unmeasured AI outputs that are sent directly to the audience without any quality gates in between.
The only difference lies in risk and visibility. Content trash embarrasses you in public, while product trash quietly erodes your business. The loop we will build in Hermes will use the same skill to score both. That way, you can manage all generated content with one quality system instead of maintaining two systems for different scenarios.
What Exactly is the Eval Loop?
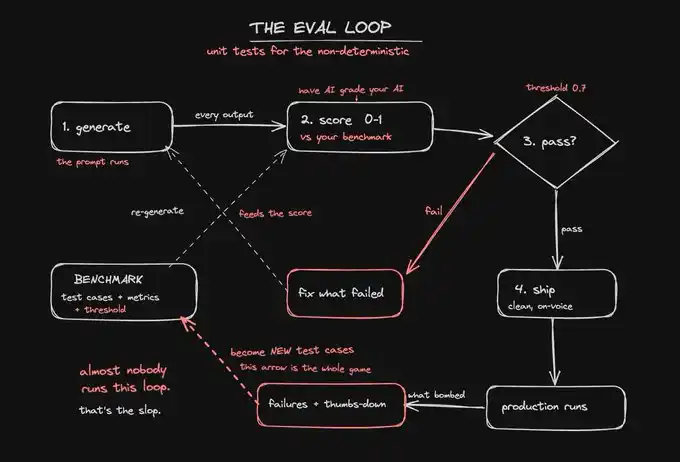
An eval loop is a repeatable test. It automatically compares the AI output to your defined standards before and after deployment, providing a score.
That's it. That's all it is. And it's the missing layer for most AI builders.
Software engineers have had this mechanism for a long time; it's called testing. You would never deploy code directly without testing and then pray for it to work correctly in a production environment. But this is exactly how the entire industry releases AI output: from the model straight to the user, relying entirely on intuition and prayer.
Almost no one has an eval loop, and the reason actually relates to the demographic. Those building things with AI today come from content, sales, product, startups, rather than an engineering background. So, "write tests for your output" has never been in their toolbox. Eval sounds like infrastructure that only "real engineers" would use, and those who need it the most tend to subconsciously feel unqualified to use it.
You can think of it as a kind of unit test for a non-deterministic system. You're not testing if the code runs, but if the output is good enough. You need to test on enough cases to ensure that one bad generation doesn't easily slip through.
An eval loop operates in three places. The system we are about to build will incorporate it into these three stages:
Pre-deployment, test your new prompts or models with a saved set of cases to ensure they have not degraded. This is regression testing to prevent a change from fixing one issue only to quietly break three others.
During runtime, score during output generation and have conditional logic intercept the failure before it reaches the user. This is fencing.
In production, continuously sample real-world execution results and score them so you can catch issues the day quality starts to decline rather than waiting for complaints a week later.
The first one, you could even set up with a spreadsheet. But if you want these three types of tests to run continuously without turning it into your second job, that's why we're putting it into the Agent.
Once quality becomes a number, AI junk content is no longer a feeling you repeatedly generate but becomes a bug that can be fixed. You can't debug a feeling, but you can debug a score that drops from 0.82 to 0.61.
Benchmark: The Three Parts You're About to Build
A benchmark has three components. Whether you are evaluating content or assessing a product, they are the same three things:
Putting these three things together, you have a quality gate. Without any one of them, all you have is a wish. The next section will explain what should go in each part, and then we will plug all three parts into Hermes.
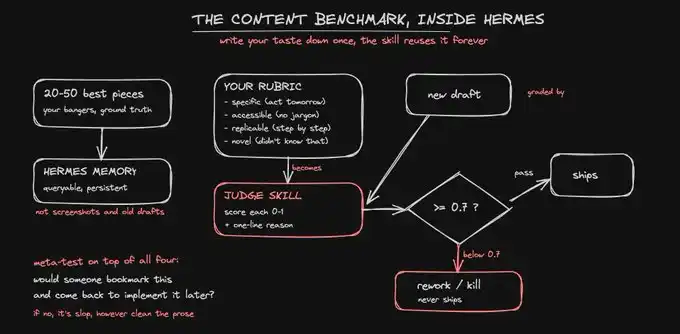
For content, your test case is your gold standard.
Identify your best 20 to 50 pieces of work: those pieces of content that truly shine, those posts that have been bookmarked, those articles you would be proud to sign your name to. This is what "good" looks like. You are not inventing a set of standards out of thin air; you are extracting the standards you have already reached at your best.
For content, your metric is a scoring rubric.
A score is only as reliable as the scoring rubric behind it. So, encode the "good content standards" you truly believe in. For content, I will score each piece based on four criteria:
Does it explain how to do something specific rather than just evoke a feeling; the reader can take action tomorrow.
Is the target audience able to understand; no jargon, no expressions understood only by insiders.
Is it well-structured, reusable, and presented in steps, not just motivational.
Is it sufficiently novel; the reader did not know before that this thing could be done this way.
The meta-standard that overlays these four criteria is: Will the reader bookmark this content and come back later to follow through?
If the answer is no, then no matter how clean the text reads, it is AI-generated junk content.
The key lies in the scoring rubric itself. A vague rubric, such as "Is this content good? Is it engaging?", will only yield fuzzy scores. A specific rubric, such as "Does this content at least include a template or manual that can be directly copied and used?", will give you scores you can trust. Only when you truly write down your taste can the judge inherit your taste.
For a product, test cases come from your logs.
You should extract the actual inputs your feature encounters from logs and real user sessions, rather than relying on just three happy path examples tested on launch day. The scenarios that truly stress the system are often those edge cases, and these edge cases are all hidden in your logs.
For a product, metrics should align with the task itself.
For each input, define what output would be considered correct, and then align the metrics with the task type. If there is only one correct label, use exact matching; if the structure must hold, use validators; if the output is open-ended, use semantic similarity plus judgment. Metrics should only do one thing: return a number. Because only with numbers can they be fit into thresholds.
For content and products, the threshold is the line you must hold.
0.7 is a reasonable starting point. Any content scoring below 0.7 must be reworked or discarded before release, without exception. The threshold is only truly effective when you never let a 0.6 result slide just because "I quite like this one." Its significance lies in removing that late-night, ego-driven judgment from decision-making.
This is benchmarking. Now, let's get it running on its own.
Setting Up the Loop in Hermes
Hermes doesn't come with an eval button by default, nor does it have a "quality" dashboard for you to click "Enable AI Content Moderation".
But what Hermes actually gives you is even better: it provides you with the raw components of an eval loop. You only need to assemble these foundational capabilities once to truly own it.
These components include: skills it can write and reuse on its own, persistent memories that grow across sessions, built-in cron, delivery capabilities to any platform, approval buttons in Slack, and a self-improvement habit ingrained in its core mechanism.
Hermes calls itself a "Growing-with-You Agent". And this growth is exactly the loop we're going to build.
So, let's start wiring. A total of six steps.
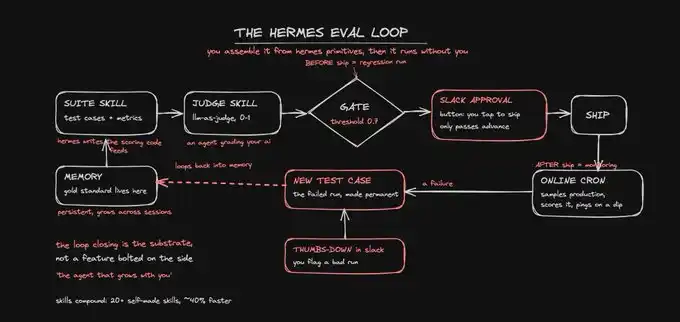
Step one, deploy Hermes to where it can reach you.
Install Hermes and integrate it with Telegram. This is more important than it sounds, as the quality gate is only truly effective when it can interrupt you. Hermes can run on over 20 channels and can natively push approval buttons in Slack and Telegram. In other words, the Agent can work in the background and gently tap you on the shoulder when it needs you to make a decision.
Secondly, load your gold standard into memory.
Hermes has a persistent memory that can grow across sessions and supports full cross-session recall. So, those 20 to 50 pieces in your benchmark, just put them in once, and they will stay there.
This content usually gets scattered across screenshots, old drafts, and miscellaneous files. But here, it becomes the Agent's long-term memory, is queryable, and serves as the ground truth for scoring.
Thirdly, turn your scoring rubric into a judge skill.
This is the core of the entire system. You only need to tell Hermes once in natural language: create a skill, take a piece of output and your scoring rubric, then return a score from 0 to 1 for each criterion, along with a reason.
This is LLM-as-a-judge: having an Agent evaluate your LLM output. With a clear and sharp scoring rubric, the model becomes a more consistent critic than you. Because it has no ego and won't hesitate to delete that sentence you were secretly proud of.
The reason it's made into a skill, rather than a one-time prompt, is that Hermes' skills are essentially procedural memories. The Agent will write them, store them, and reuse them. You just need to encode your taste once, and it can continue to score every output thereafter.
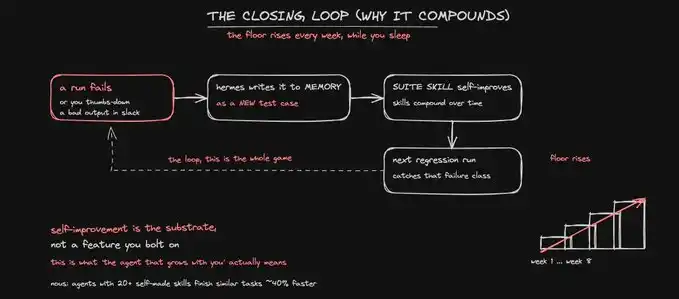
Moreover, skills have a compounding effect. Nous found that an Agent with over 20 self-created skills speeds up by 40% in similar tasks because they no longer need to rediscover the process repeatedly. Your judge also becomes sharper the more it runs.
Fourthly, turn your test suite into a skill, not just a spreadsheet.
Your test cases and metric functions will be combined into a skill saved and versioned by Hermes. The metric library will determine based on the specific task: precise matching for classification tasks; regular expressions for extraction tasks; JSON validator and key-value validator for structured output; and semantic similarity for generative output.
For those open-ended tasks, your judge skill will be used. Hermes will autonomously write scoring logic. You only need to describe the task, and it will set up the corresponding metrics. All of this is consolidated in one place, managed by the Agent itself, rather than scattered on a spreadsheet you'll eventually lose track of.
The fifth step is to guard the release gate with regression testing and an approval button.
This is the highest-leverage habit in the entire system, yet also the one least sustainable manually in the long run. Therefore, we entrust it to the Agent.
Once the workflow is connected, any changes—new prompts, model replacements, adjusted pipelines—will automatically trigger the test suite. Hermes will rerun all cases, calculate the score delta compared to the baseline, and instead of silently deploying, it will remind you on Slack: "The score dropped from 0.81 to 0.74, with two cases regressing. Do you approve?"
Only after you click the approval button will it proceed.
You can use /goal to keep it focused on this task continuously, allowing the Agent to iterate over multiple rounds with the same goal in mind. For larger tasks, its multi-Agent dashboard can break down the execution flow, score in parallel, and schedule execution times.
This way, the quality gate becomes a permanent process, rather than something you must remember to do manually.
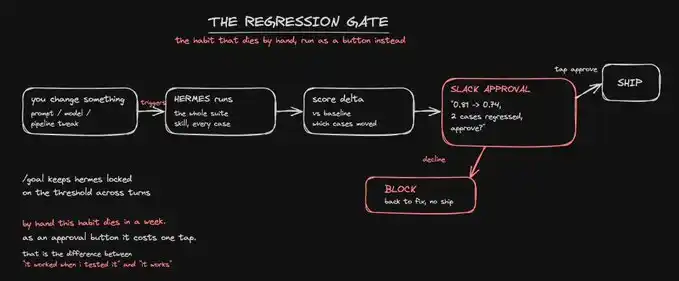
The sixth step is to monitor the production environment with cron and complete the closed-loop.
Hermes has built-in cron capability to send results to any platform. Thus, you can schedule a recurring task, sample real execution results, score them using the same judge skill, and privately alert you when the score falls below the threshold.
This allows you to discover issues on the day the quality starts to decline, rather than waiting for a week until a customer complains.
"Eval score has dropped" is an issue you can address immediately; "Seems like a customer is somewhat unhappy" is not.
Next is the crucial part to kickstart the entire system's compounding.
When you thumbs-down a poor output in Slack, Hermes will write it back to the skill test suite as a new test case. That failed run becomes a permanent check.
Moreover, since self-improvement is at the core of Hermes, not a bolted-on feature, this test suite automatically becomes more robust every week.
While you sleep, the quality baseline continues to rise.
Once this system is truly up and running, the good state will be very specific: a piece of content scoring below 0.7 on your scale will never be published. Any product change that dips any metric below the baseline will halt deployment until your personal approval.
And the scoreline in production will stay steady or continue to rise. The day it begins to drop is the day Hermes alerts you, not a week later when user churn data shows.
The Part Nobody Wants to Hear
The reason your AI output is unstable isn't because you can't write prompts well or because the model isn't smart enough yet.
It's because you've only been running the generation step, not the quality step. You've built a half-baked system and have been blaming the half that actually works.
The fix isn't to find a better prompt, but to fill in that missing layer.
Define what good is, turn it into a number, evaluate every output against that number, block anything below the standard, and complete the loop to raise the quality baseline automatically every week.
Now, this layer isn't some "do it later" project; it's a system that can run on your own machine, through an Agent, in six steps.
Once you achieve this, AI garbage output won't be a random occurrence to deal with; it will be something you catch every time before heading out, just like a true factory intercepts defective products before they reach the customer.
Prompts were never the system.
The eval loop is the system. Hermes is where it runs.
Now, you own it.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia