Editor's Note: Lance Martin from Anthropic believes that the key usage of Mythos-level models like Claude Fable 5 is not constant manual prompting by humans, but designing self-correcting loops for the model.
The article proposes two core techniques: first, setting clear goals or evaluation criteria through mechanisms such as /goal and Outcomes, allowing the model to iteratively execute, receive feedback, adjust its approach, and continue iterating; second, utilizing memory (cross-session memory) to help the model record failures, investigate causes, validate conclusions, and distill experiences into reusable rules for the future.
In experiments like Parameter Golf and Continual Learning Bench, Fable 5 excels in structural exploration and persistent long-term tasks compared to Opus 4.7 and Sonnet 4.6, converting memory into effective improvements for subsequent tasks.
The core idea of the article is: rather than directly manipulating the model, it is better to design the environment, feedback mechanisms, and memory systems to enable the model to strengthen itself through iterations.
Below is the original text:
Models like Claude Fable 5, of Mythos level, have already changed the way many people work within Anthropic. I would like to share two techniques to help everyone better leverage the capabilities of such models.
Self-Correcting Loop
Recently, there has been a lot of interest in "loops." @bcherny once mentioned, "My job is to write loops." Having the model continuously optimize around an evaluation standard is a common method to improve task performance: /goal in Claude Code and Outcomes in Claude Managed Agent are foundational capabilities that allow you to apply this general method to specific tasks.
As we mentioned in the Prompt Guide, Fable 5 excels at self-correction within loops. A well-designed goal or evaluation criteria is akin to adding a feedback mechanism to the environment Claude operates in. This way, Claude can first perform the task, then collect feedback through the goal or evaluation criteria, self-correct, and continuously progress until the goal or evaluation criteria are met.

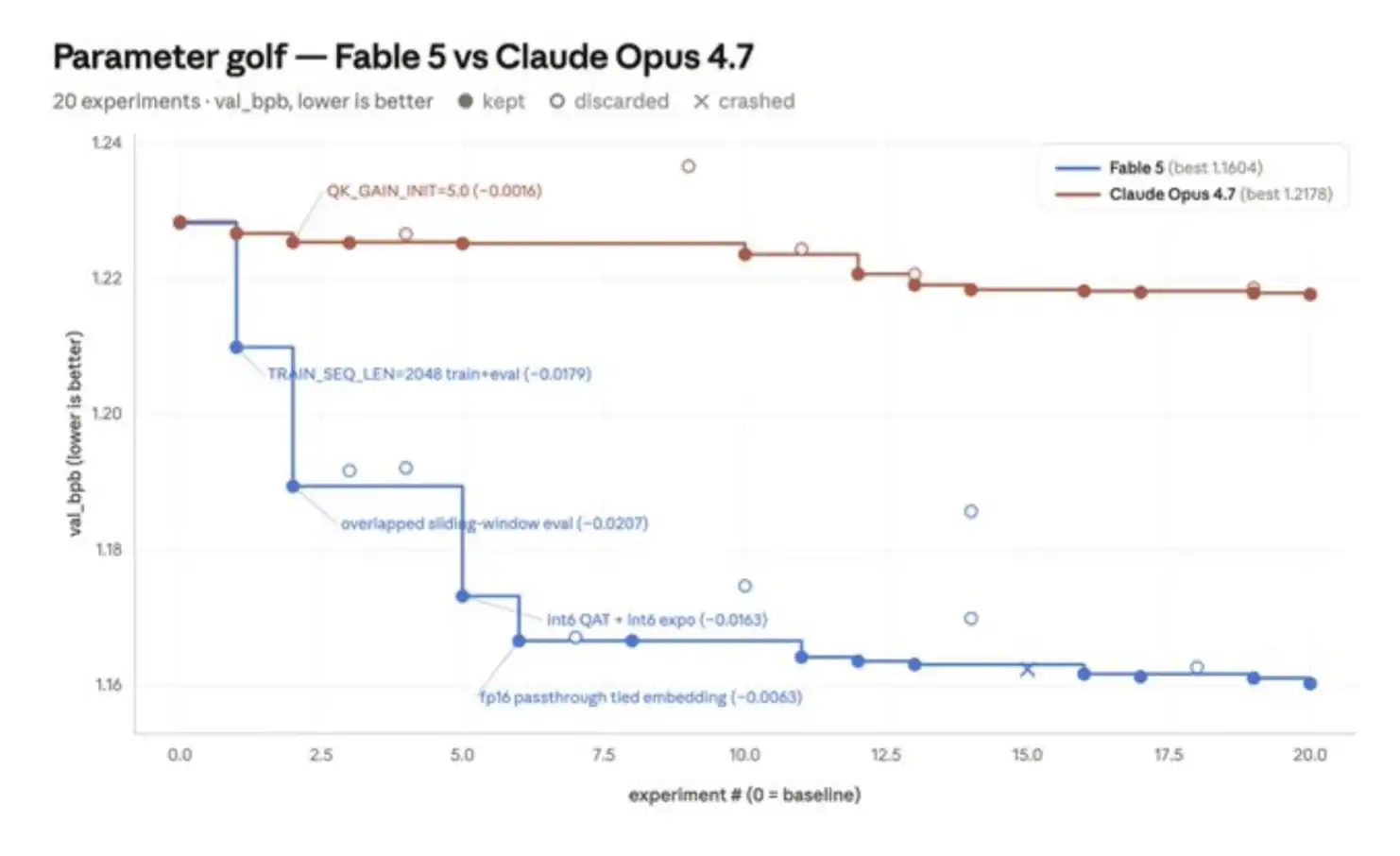
I'm sharing a small example I used to test Fable: Parameter Golf. This is an open-source machine learning engineering challenge with the goal of training the best-performing model on 8 H100 GPUs in under 10 minutes, while keeping the final artifact under 16MB.
It's a bit like @karpathy's autoresearch project: this challenge tests whether an Agent is capable of modifying the underlying training code, a train_gpt.py file; initiating training; polling logs; reading scores; and deciding what experiment to run next.
In this challenge, I compared Fable 5 and Opus 4.7 using Claude Managed Agents (CMA). CMA provides an Agent execution framework and a managed sandbox, making it ideal for running long-duration tasks with Fable 5. In the Parameter Golf test, I had CMA access a self-hosted sandbox with 8 H100 GPUs.
There's a subtle but crucial point here: who judges the results is key. We've found that models often struggle when critiquing their own generated content. Prithvi Rajasekaran has written about this in our engineering blog.
We found that for Fable 5, using a validation-style sub-Agent often produces better results than self-critiquing, as the scoring is done in an independent contextual window. The Outcomes feature in CMA will automatically start a scoring sub-Agent to handle this.
In each test, I provide a scoring criteria file with nine checkable standards, such as running a baseline experiment and completing 20 experiments. Subsequently, I allow Parameter Golf to run for a maximum of 8 hours. Only when the Outcomes scorer confirms all experiment criteria are met will Claude be allowed to stop working.
The result is that the improvement in the training process with Fable 5 is about 6 times greater than Opus 4.7. If experiments are divided into structural experiments, such as changing the model architecture, and scalar experiments, such as adjusting a constant, Fable 5 tends to bet on more significant structural changes and demonstrates greater robustness. For instance, it persisted with a quantization regression problem, ultimately achieving the largest single boost.
In contrast, the first experiment of Opus 4.7 brought a slight improvement, but almost all subsequent experiments followed the same template: adjust a scalar, measure the result, and retain it if the result is positive.
Memory
Memory is another area where Fable excels. It can be understood as a cross-session external loop: Claude writes memories in one session, which can then be retrieved in future sessions.
@pgasawa and the team recently released Continual Learning Bench 1.0, so I also wanted to use it to test the differences between Fable 5 and early models.

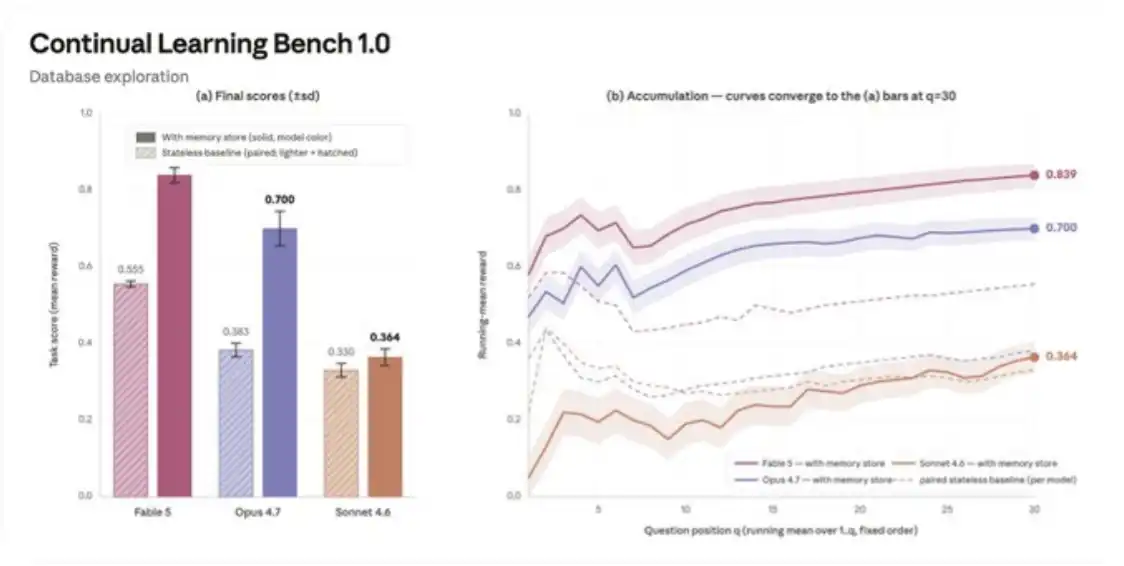
In this benchmark task, I compared Fable 5, Opus 4.7, and Sonnet 4.6. This task required the Agent to answer a series of questions consecutively while accessing an SQL database. Each question was an independent Agent session and had memory capabilities.
For this, I used a CMA with memory capabilities. It provided each Agent with a mounted file system that could be shared between different sessions.
For this task, to effectively utilize memory, one usually needs to go through a progressive process: Failure (answer incorrectly and record it), Investigation (understand the cause before proceeding), Verification (turn diagnostic results into checked facts), Distillation (transform verified results into general rules), and Reference (directly read rules later instead of re-deriving them).
Sonnet 4.6 stayed around Step 1: its memory storage was more like a series of failure notes and undecided guesses, such as "Maybe should use prc instead of prc_usd?" It rarely referenced previous notes. To improve performance, task-specific memory usage instructions need to be incorporated.
Opus 4.7 progressed to around Step 3: it would create a schema reference document and annotate uncertainties, like "prc might be priced in cents? Needs verification." However, its verification coverage was not high: it only covered 7% to 33% of the questions, with a median run result of about 17%.
Fable 5 tended to complete the entire progressive process: in its best-performing runs, its verification coverage reached up to 73%, validating 22 out of 30 questions, and would distill learned content into general rules to aid future tasks.
Therefore, rather than directly prompting and continuously guiding Fable 5, a more effective approach many times is to design a feedback loop, allowing the model to self-correct based on the environment, such as using /goal or Outcomes; while also enabling it to manage its own context, for instance, through a memory mechanism.
Here, I've only shared a few small-scale experiments I've conducted myself, but Fable 5 is well worth personally testing on high-difficulty tasks, especially when incorporating a self-correction loop or memory mechanism.
If you're interested in getting started, you can refer to our documentation or directly query the latest version of Claude Code. It can utilize the built-in /claude-api skill to introduce you to Fable 5, including Prompt best practices, /goal, Claude Managed Agents, or other API functionalities.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia