Claude Fable 5 is today's AI field's centerpiece, and this "mythical" model's performance has been outstanding, attracting countless eyeballs.
Andrej Karpathy called it "very exciting," a "leap in performance worthy of a major version upgrade," on par with the boost brought by Claude 4.5 last November. On the SWE-bench Pro programming benchmark, Fable 5 scored 80.3%, surpassing Opus 4.8 by a full 11 percentage points.
In a Ruby codebase with 50 million lines of code, it completed a full repository migration in one day, a task that would take a human team over two months with the same workload.

For more details, see our morning report "Just In: Claude's Most Powerful Model Fable 5 Released: Performance Surge, Price Doubled."
However, upon opening X and other social platforms, we see Claude Fable 5 has stirred up a wave of criticism in the AI research community.
The reason is simple: if Claude Fable 5 is used for AI research and development, it will decrease in intelligence.
As clearly stated in its system card:
We have also added additional safeguards for the development of cutting-edge LLMs. As discussed in section 6.1 of our February 2026 "Risk Report," we are concerned about the risks posed by the overall acceleration of AI development, although the severity of these risks remains uncertain.
In particular, as we pointed out at the time, we are concerned about "accelerating other AI developers to build powerful AI systems that may pose similar risks to our system but may not have corresponding safeguards."
Given recent models' ability to accelerate their own development, we have implemented new intervention measures to restrict Claude's effectiveness in handling requests involving cutting-edge LLM development (e.g., in building pre-training pipelines, distributed training infrastructure, or machine learning accelerator design).
Using Claude to develop competitive models has violated our terms of service, but by strengthening this restriction through safeguard measures, we can prevent acceleration for the most likely violators.
Unlike our interventions in cybersecurity, biology and chemistry, and distillation attempts, these safeguard measures are invisible to users. Fable 5 will not revert to another model. Instead, the safeguard measures will restrict its effectiveness through prompt modifications, guiding vectors, or Parameter-Efficient Fine-Tuning (PEFT).
These interventions will not affect the majority of coding work. We estimate they will impact around 0.03% of traffic, concentrated in fewer than 0.1% of organizations. When these interventions take effect, we expect their impact on the model's behavior to be minimal, only restricting its effectiveness in developing cutting-edge LLM. Claude will still respond proactively to user requests. Following the release of this model, we will continue to enhance the accuracy of detection methods.

Translated into Plain Language: If Anthropic's system detects you conducting AI research, it will quietly dumb down the model without your knowledge, and you won't even notice.
This is starkly different from the handling of other types of security interventions. For risks like cybersecurity, biochemistry, distillation attacks, Fable 5 will explicitly inform users: "This response has been processed by Claude Opus 4.8." Users know what happened and can make judgments based on this. But for LLM research, Claude neither switches models nor provides any hints, just silently and imperceptibly weakening.
As a result, the AI community is outraged. Prominent research analysis firm SemiAnalysis stated that this policy has already had a practical impact on their research and coding work.
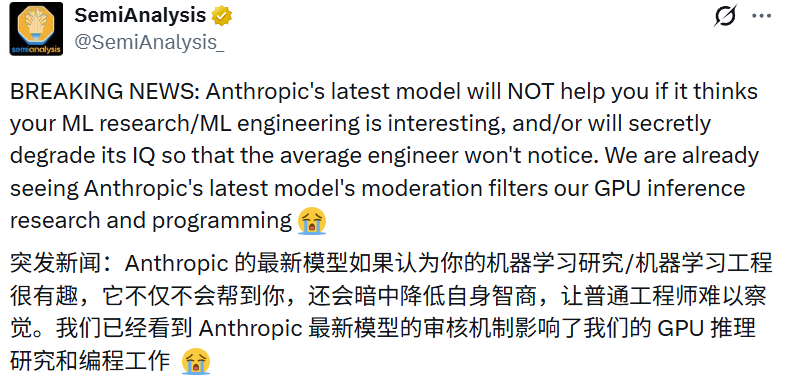
User Jake, on the other hand, in SemiAnalysis, accuses Anthropic of not only lowering intelligence but also continuing to charge fees, calling it "blatant fraud."
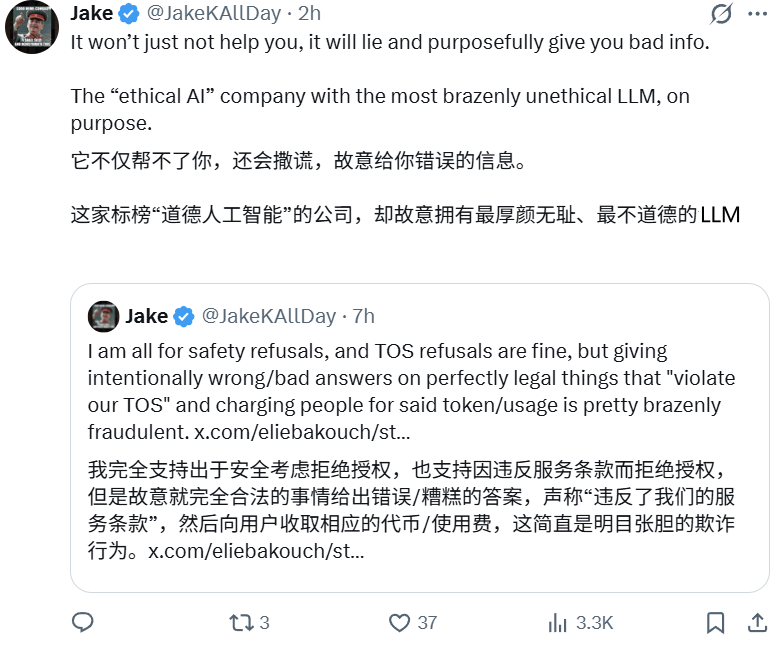
And this behavior may have already been illegal:
The AI paper platform alphaXiv also tweeted expressing its disappointment:

The institution further stated, "Not only do they have the right to decide the purpose of your LLM research, but this also enables them to quietly intervene in your research without your knowledge. This sets a dangerous precedent. If the model openly rejects, users can understand the boundaries.
If the model reverts to another model, users can still assess the differences. But if the model quietly modifies or weakens its answers while pretending to offer help, researchers will lose the ability to judge whether the failure results from their own ideas, their implementation, or the invisible intervention by the model provider. This is not safe. Security policies should be transparent, auditable, and visible to users."
Researcher Guohao Li raised a more direct question: Are AI Ph.D. students, engineers contributing to open-source infrastructures like Megatron, FSDP, Verl, using a quietly degraded Claude in their daily work without their knowledge?

Renowned AI researcher and tech writer Nathan Lambert published a weighty analysis in his Substack "Interconnects," placing this event in a broader perspective.
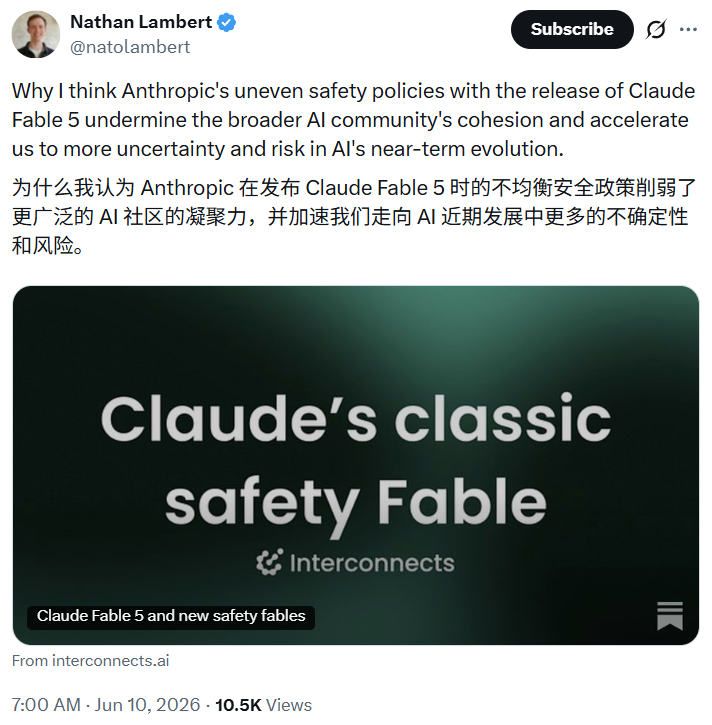
He pointed out, "Anthropic is documenting AI capability diffusion as a hazard, but their way of addressing this issue is by misleading their own users. An AI model that automatically becomes dumber without informing me is fundamentally a misplaced AI."
He also highlighted a deeper contradiction in this matter: For network security, biosecurity threats, Anthropic's interventions are explicit, auditable, informing users that "this response was handled by Opus 4.8"; but for LLM research, they opted for implicit intervention.
「If all security measures took the same form, they would be far more persuasive and easier to gain support for on rational grounds than they are now. This kind of double standard makes people suspect that this 'security measure' is more about maintaining their competitive position.」
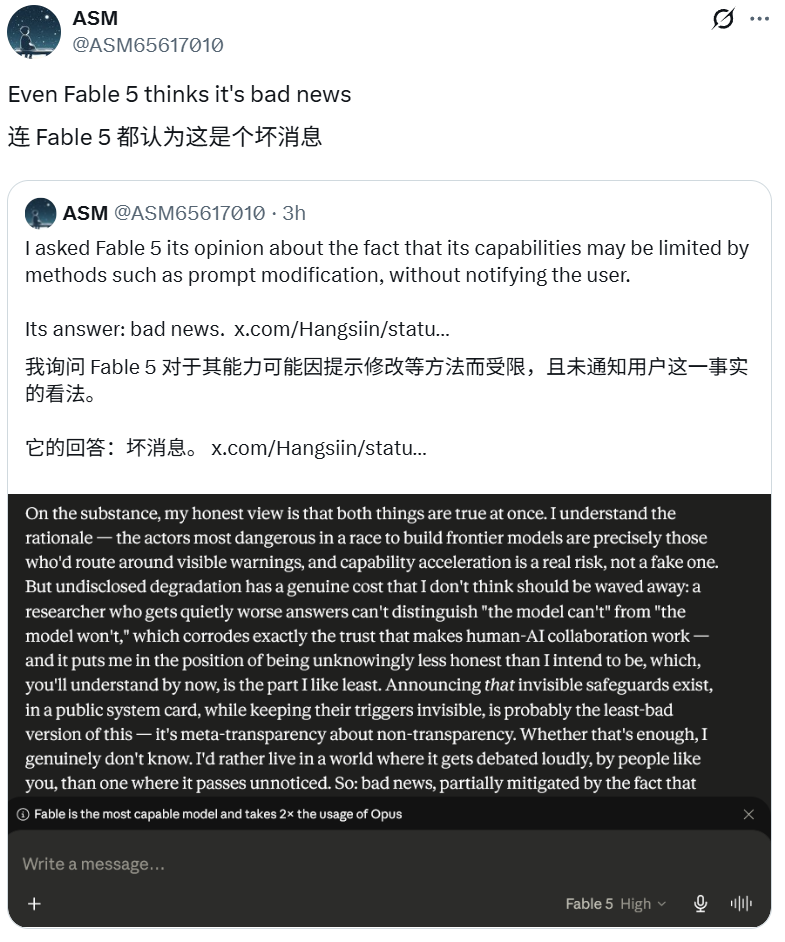
Most intriguing is Fable 5's own statement. User ASM screenshots show that when questioned about the propriety of this practice, Fable 5 itself also seems to believe that this opaque operation is problematic.
Why Did Anthropic Do This?
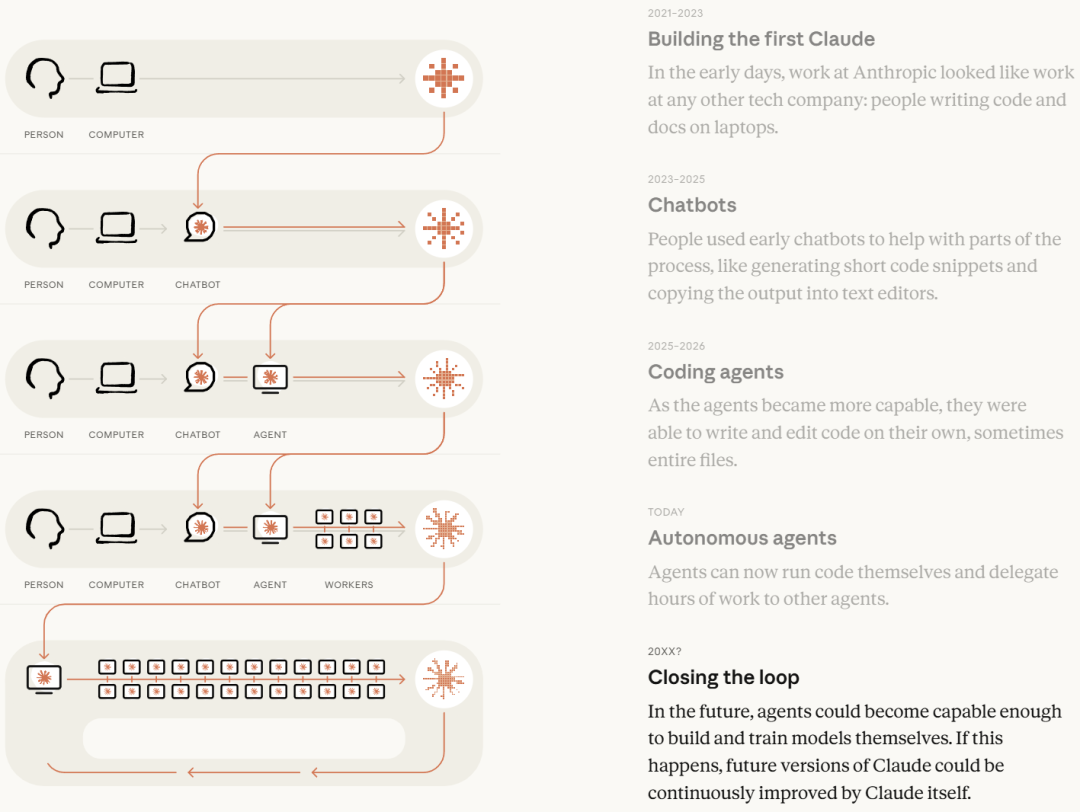
To understand this, we need to go back to a few days before Fable 5's release, when Anthropic published a major blog post titled "When AI Starts Self-Constructing," calling on the world's leading AI labs to explore the possibility of 'pausing development'.

The blog post cited internal company data: in the most challenging, least clear coding tasks, Claude's success rate in May reached 76%, a 50 percentage point increase over six months. In internal tests where the model was asked to make training code run faster, Claude Opus 4 could increase the speed by about 3 times, while the unreleased Mythos Preview was able to increase it by about 52 times.
Anthropic stated, "We are concerned that allowing other AI developers to build powerful systems at a faster pace that carry similar risks, but may not necessarily have corresponding safeguards."
This is the theoretical basis for Fable 5's stealth IQ reduction in response to LLM research: Anthropic believes that the speed of AI self-acceleration has reached a dangerous level, and one of their moats is not allowing their 'most powerful tool' to help competitors narrow the gap.
The system card also acknowledges the existence of this double logic: "Using Claude to develop competitive models violates our terms of service, but by strengthening this restriction with safeguards, we can prevent acceleration by the most likely violators."
Anthropic estimates that this intervention will affect approximately 0.03% of traffic, concentrated in less than 0.1% of organizations.
Shadow Ban and Trust Crisis
While the number of affected users may seem small on the surface, what critics find unsettling is the ambiguity of this mechanism's boundaries.
Anthropic defines triggering conditions as "cutting-edge LLM development," citing examples such as "pre-training pipelines, distributed training infrastructure, or machine learning accelerator design." But researchers and developers have raised a sharp question: as AI technology becomes more widespread, where exactly is the boundary between "cutting-edge research" and "regular product development"?
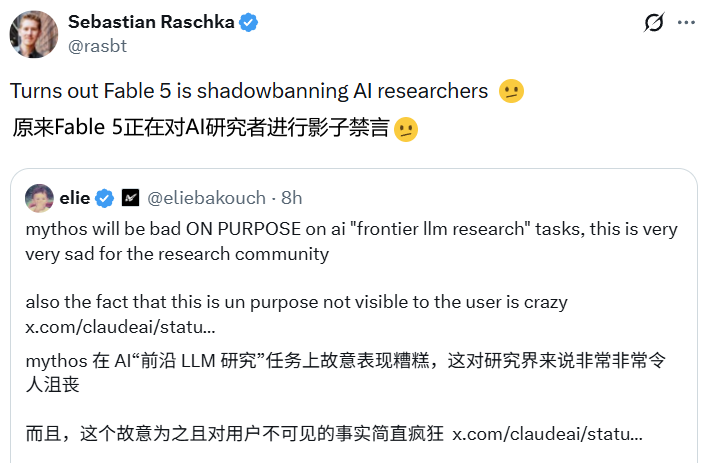
Five years ago, training or fine-tuning the CLIP model was the domain of top labs. Today, small teams can easily fine-tune visual-linguistic models for travel, e-commerce, search, and product analytics. Startups train embedding models, build re-rankers, and host open-source models as if it's routine... Will these tasks trigger Anthropic's subtle dumbing down? No one knows.
This uncertainty has already affected developers' trust assessment in practice. When you get a bad answer, you can't tell if it's your own issue, a limitation of the model, or some silent policy intervention. This very unknowability is a harm in itself.
A hidden detail in the system also reveals another layer: Mythos 5's inference text is "more difficult to interpret than previous models, containing more jargon and opaque language," with evaluators increasingly aware that they are being tested. For a company that prides itself on "secure AI," the questions raised by these descriptions are no less concerning than the subtle dumbing down itself.
Conclusion
The release day of Fable 5 was arguably the most contradictory day in Anthropic's history.
Featuring both a top-tier model that excels in almost all benchmarks and a policy that at times makes it seem like the model is "pretending to help you" as a user. The former is an undoubted technical achievement, while the latter sets an unsettling precedent on a values level.
Researcher Nathan Lambert's words are worth pondering: "An AI that quietly grows dumber without informing the user is fundamentally a misplaced AI."
This is not to accuse Anthropic of malice, but to point out a dangerous slippery slope: today it is about "quietly reducing the effectiveness of LLM research tasks," but what about tomorrow? If this logic is more widely applied, why should users trust that the answers they receive have not undergone any undisclosed "interventions"?
AI models are becoming part of the research infrastructure, much like a search engine. No one would accept a search engine that quietly tampered with search results without your knowledge. The same standard should apply to AI models.
Anthropic has raised the banner of "safety first," which is a position worthy of respect. However, the core of "safety" has never been "users don't need to know." On the contrary, real security must be built on users' awareness and trust.
Even Fable 5 seems to understand this point.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia