Anthropic has just handed in a flawless report card on paper.
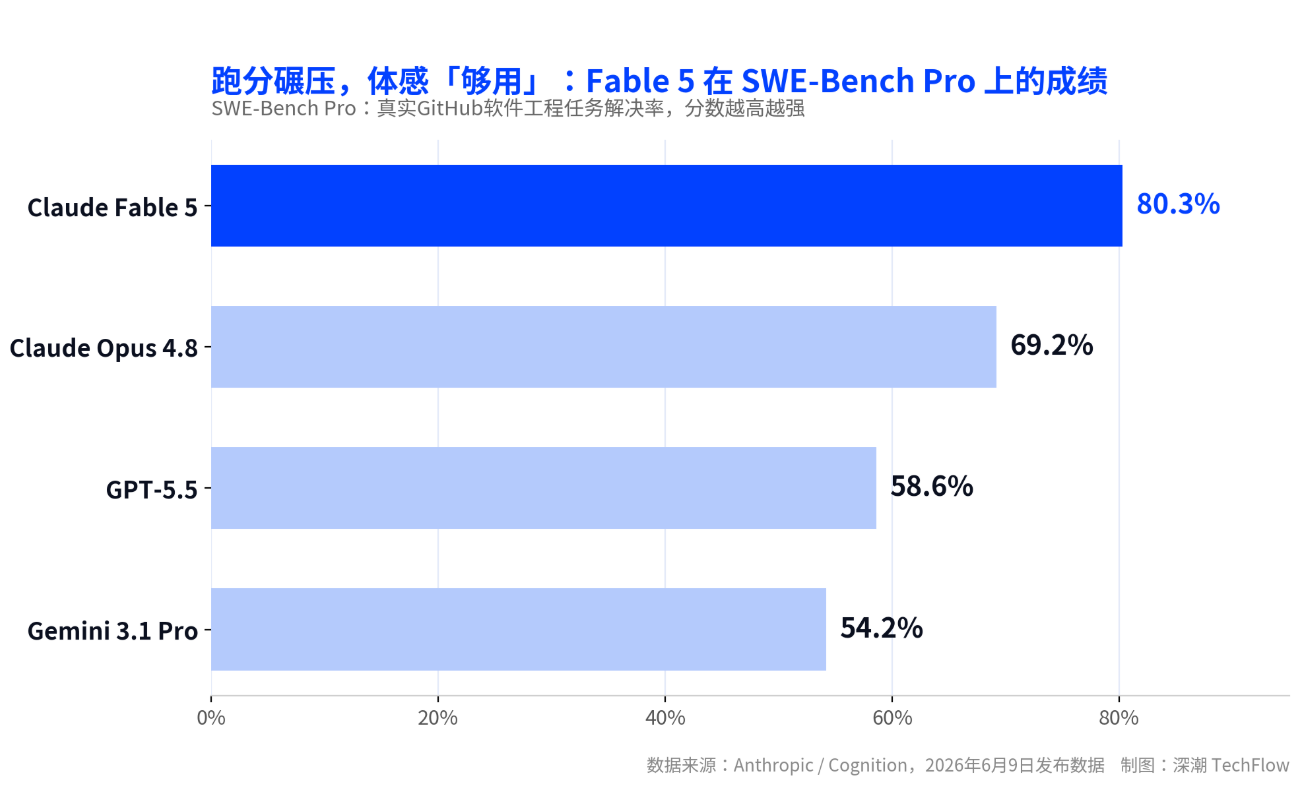
Released on June 9, Claude Fable 5 is the company's first publicly available Mythos-tier model, scoring 80.3% on the real-world software engineering task benchmark SWE-Bench Pro, outperforming its own previous flagship Opus 4.8 by about 11 percentage points and surpassing GPT-5.5 by over 20 percentage points.
But users' reactions poured cold water on it.
Three days after the release, a hot post on the r/artificial subreddit (weekly visitors: 305,000) was titled: "Claude Fable made me realize I don’t need a better model."
The poster, Axi0m-22, said that after running Fable for a while for security research and daily tasks, he almost immediately switched back to Opus for coding and Haiku for miscellaneous work. He made an analogy: It's like holding an iPhone 14 and watching the release of iPhone 17, "You know the new one is better, but you’re like, 'Eh, mine’s pretty good.'"
Upvoted Area Dominated by "It's Good Enough" Camp: Model Aesthetic Fatigue Becomes Mainstream Sentiment
The top-ranked comment received 42 likes: "Other than a larger context window, ever since Opus 4.5, I no longer feel the need for a stronger model."
Another user, hyprlab, with 13 likes, stated: "Switching to a model that burns tokens more aggressively, I don’t see the benefit for my workflow; Opus 4.8 in high-power mode is already comfortable enough."
Behind these comments lies a common cost ledger.
Fable 5's API is priced at $10 per million input tokens, nearly double that of Opus 4.8. User siromega37 put it bluntly: "Higher token consumption, but no return on investment. I feel we are witnessing a plateau, and the bubble will eventually burst."
User hobopwnzor provided a more systematic interpretation: "We have been at the top of the S-curve for a while now. Recent progress has mainly come from tool invocation and peripheral engineering, not from the model's own capabilities."
Security Firewall Identified as the Biggest Bottleneck: "90% of Use Cases Directly Rejected"
If "sufficient" is still just a sentiment, then complaints about the security firewall are a specific product issue.
According to the official explanation from Anthropic, Fable 5 shares the same underlying model as Mythos 5, which is only open to a few institutions, with the difference being that Fable is equipped with a security classifier: requests involving cybersecurity and other high-risk areas will be intercepted and handled by Opus 4.8. The company states that this mechanism is tuned conservatively, triggering in less than 5% of sessions on average and causing false negatives on harmless requests.
In this Reddit post, the perceived trigger rate is evidently much higher than 5%. User jradoff, who received 17 likes, mentioned that when he had Fable check the security of his own code, it "basically rejects handling anything related to security," and he is then rolled back to Opus. Another comment with 12 likes was more blunt: "90% of what you want to do with it will be rejected, making it useless."
Paying users are even more disgruntled. User kaitava, subscribed to the $200 tier, wrote, "I paid double the usage fee, wanting it to perform a security review, only to be downgraded to Opus. Now I dislike everything about it and am just waiting for OpenAI to catch up."
For a flagship product that emphasizes capability leap, the "usability cost paid for security" is becoming a core variable for users deciding whether to foot the bill.
Opposing Voice: Power Users' Experience Feels Like "Night and Day"
Beneath the trending posts are not without dissenters, and the opposing camp's image is quite clear: the heavier the task, the higher the praise.
User Phylaras' comment received 15 likes: "Fable has made a substantive difference for me. For complex tasks that demand a significant contextual window, it unearthed errors that were previously unnoticed." A user claiming to work on high-energy physics simulations stated that a single simulation model easily consists of 8000 to 10,000 lines of code, with interactions between hundreds of models, saying, "Having a model that can independently work continuously and understand environmental details is highly anticipated for me."
The most vigorous rebuttal came from user Navetz: "Honestly, anyone who has used this model would think this post is nonsense. To me, it's clever to the point of being unrecognizable, and I've been using it non-stop. I explained to my non-tech-savvy friend: It's like going from a college basketball player directly to an NBA starter."
Some have also proposed a compromise in usage. User ready-eddy suggested treating Fable as a "planner and fixer," rather than a daily "builder," unless you don't mind burning money. Another comment summed it up more like a user manual: Using Fable for spreadsheets is choosing the wrong model, just as using Haiku to run complex tasks for 16 agents is also choosing the wrong model. "There are no inherently bad models, only models used in the wrong scenarios."
After Decoupling Benchmarking and User Experience, Will Public AI Become Stronger?
One of the most interesting comments in this debate shifted the topic from the product to the industry structure.
User KedMcJenna presented a "Public AI Freeze Hypothesis": Models accessible to the general public may forever remain at the current level, while corporate and government elites will continue to have access to stronger private models, "We know of at least Mythos, and there are likely even stronger models that we will never hear about."
This comment points to a fact: Mythos 5 is indeed not open to the public and is currently only available through the Project Glasswing initiative to network defense agencies and critical infrastructure enterprises.
Considering benchmarking and public sentiment together, the conclusions are not contradictory.
Benchmarking measures the upper limit of capability, while the Reddit top-upvoted area reflects the ceiling of daily needs. When the tasks of the majority of users were already satisfied in the Opus 4.6 era, a stronger model can only prove itself in extreme scenarios such as physical simulation and ultra-long contexts. Model vendors are no longer facing the question of "can or cannot do," but rather "who needs it, is willing to pay how much, and can tolerate how much security friction."
Three days after its release, Fable 5 received two completely different report cards in benchmark rankings and public opinion. Which one is closer to the truth will depend on Anthropic's upcoming adjustments to the security classifier speed and the wallet voting of heavy users.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia