TL;DR
· Claude $20 Subscription Cost Breakdown Chart, splitting a monthly AI fee into model company, cloud computing power, GPU, electricity, and supply chain.
· AI subscriptions have ongoing inference costs and cannot directly apply the high gross margin assumption of traditional SaaS.
· Related Entities: OpenAI, Anthropic, Microsoft, Amazon, Google, NVIDIA (NVDA), TSMC, SK Hynix, Samsung, Micron, data centers, and power grid.
An estimate chart breaking down Claude Pro's US $20 monthly payment to model company, cloud computing power, GPU depreciation, electricity, and supply chain is prompting investors to reconsider how AI application revenue should be valued.
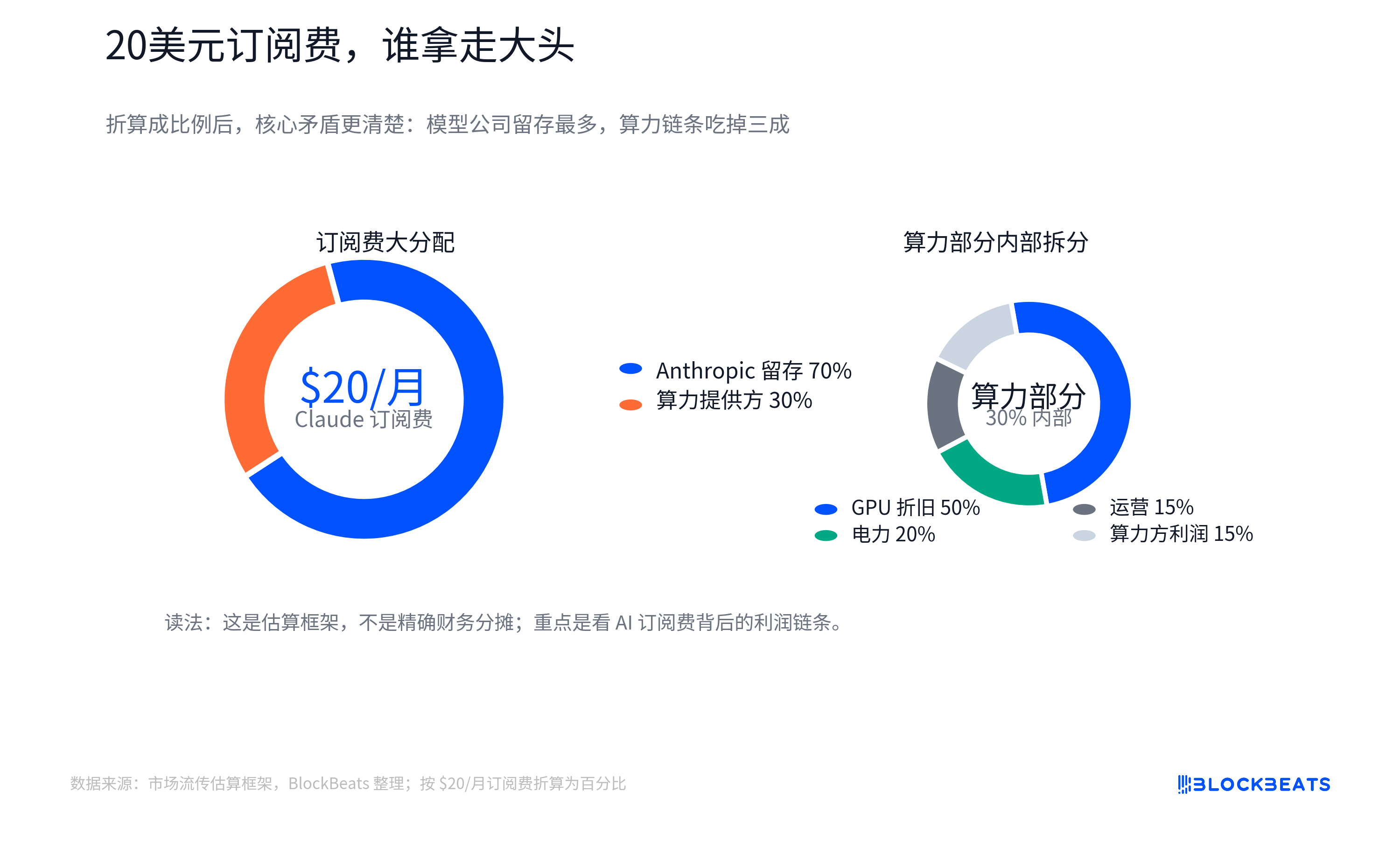
This chart is not official allocation data from Anthropic, AWS, or NVIDIA, nor can it be treated as the actual books of any company. Its value lies in posing a more fundamental question: how much of the subscription fees users pay to AI applications can be retained as software gross margin, like traditional SaaS?
The valuation logic for traditional SaaS is quite clear. After the software is developed, selling an additional account usually does not incur high additional costs, and the gross margin for mature pure software companies is commonly seen at 70% or even 80% and above. Investors are willing to pay high multiples because once the revenue scales up, there is an opportunity for the profit margin to continue to rise.
The trouble with AI applications is that behind every user query, code writing, file analysis, or agent invocation, there is a consumption of GPU time, electricity, memory bandwidth, and cloud resources. While the surface appears to be a fixed monthly fee, at the core, it is a cost chain that varies with usage. Light users may have high gross margins, but heavy users continuously run tasks within available limits or related tool packages, causing costs to escalate rapidly.
Therefore, the $20 breakdown chart is not challenging how many dollars a particular company takes away but rather whether "AI application revenue is inherently equal to SaaS revenue." AI companies must prove their worth with high multiples not only by demonstrating that users are willing to pay but also by showing that the gross margin weighted by usage can continue to improve.
Behind Subscription Fees Lies a Chain of Inference Costs
The biggest difference between AI subscriptions and regular software subscriptions is that the marginal cost of "using once" is no longer close to zero.
In traditional SaaS, when a team opens an additional account, the service provider also incurs server, customer service, and bandwidth costs, but these costs usually do not increase linearly with each click. The truly expensive elements are upfront development, sales, and customer acquisition. Once the product is scaled, a considerable portion of new revenue can be retained.
The large-scale model product is different. Users input questions, and the model generates answers. This process is called inference, which is the actual computation when the model is invoked by the user. A Token is the basic unit of measurement for the model to read and write text. The more questions a user asks, the longer the context, and the more complex the generated content, the more tokens and computational power are consumed.
This creates a contradiction between fixed subscriptions and variable costs. Claude Pro's monthly subscription price in the United States is around $20, a price that is subject to adjustments based on region, taxes, and Anthropic factors. Users see a fixed price, but the model company faces widely varying patterns of usage. Some people only write emails and look up information, while others process long documents, run code tasks, or invoke more complex automation processes.
A split diagram circulating in the market attempts to visualize this: within the $20, a portion goes to the model company, and a part is paid to the cloud and computing power provider. The costs of computing power include electricity, maintenance, and GPU depreciation. GPU procurement flows upstream to NVIDIA, TSMC, HBM (High Bandwidth Memory) suppliers, optical modules, ODMs, and power-related companies.
Here, "GPU depreciation" can be understood as the fact that expensive GPUs are not allocated to a single calculation but are gradually spread across AI services based on the period of use, intensity of use, or accounting standards. The actual allocation is influenced by package limits, the proportion of light and heavy users, internal settlement prices at cloud providers, reserved computing power discounts, GPU utilization rates, and depreciation periods. The average cost is also not equal to the marginal cost.
What investors really need to focus on is the direction: AI application companies should not only disclose revenue growth but also address whether the growth in revenue is synchronized with the increase in computing power costs. If usage expansion outpaces model efficiency improvement, the higher the subscription revenue, the more apparent the gross margin pressure may be. Only with sufficient efficiency improvements can model companies have the opportunity to approach a profit structure similar to software companies.
Infrastructure Gains More Definite Revenue First
At present, the increase in AI usage is more directly flowing towards infrastructure rather than entirely settling at the application layer.
Whether users are using the model in Claude, ChatGPT, Gemini, or internally within an enterprise agent, inference ultimately comes down to computing power, electricity, memory, and networking. Product replacements may occur at the application layer, but the underlying resource consumption is more rigid. As long as AI usage continues to rise, cloud capital expenditures, GPU purchases, HBM demand, and data center power consumption will be driven.
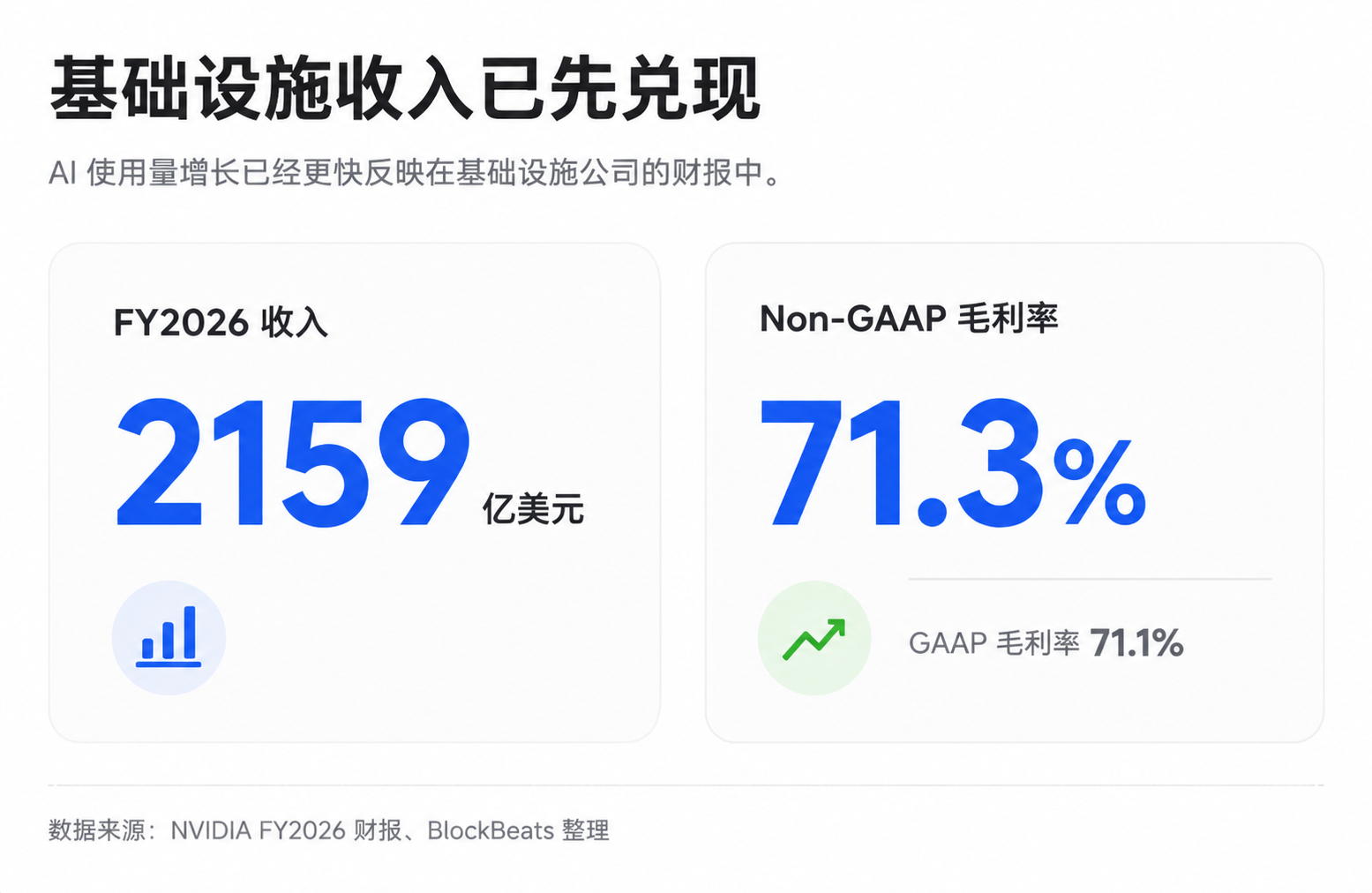
This is also why infrastructure chains such as NVIDIA, TSMC, and SK Hynix have been continually reassessed by the market. NVIDIA has maintained a high overall gross margin rate in recent years. For FY2026, the GAAP and non-GAAP gross margin rates were approximately 71.1% and 71.3%, respectively, with subsequent quarter guidance also staying at a high level. It is worth noting that specific quarters may be affected by certain expenses, and public financial reports do not always clearly separate the true gross margin structure of AI data centers. However, the pricing power of scarce infrastructure has already been reflected in the performance.
HBM is the most typical link on this chain. It is not ordinary memory but a key component in AI accelerators that supports high-throughput computing. As model scale, context length, and concurrent inference requirements increase, AI chips rely more on high-bandwidth memory. Supply chain estimates show that HBM's share of the cost in the new generation of AI chips has increased, which is also a key reason SK Hynix, Samsung, and Micron have been repriced in the AI cycle.
Power and data centers have also shifted from background costs to the main investment theme. The energy consumption of a single ordinary text query may not be exaggerated, but complex agents, long contexts, code generation, and multi-turn tasks will amplify the computational load. For cloud providers and data center operators, the key is not how much power a single query consumes but when massive inference requests occur continuously, cluster utilization, electricity prices, cooling, data center capacity, and power grid access capacity all become costs and bottlenecks.
The advantage on the infrastructure side is faster performance validation. Cloud providers' AI capital expenditures have already taken place, NVIDIA's revenue and gross margin are reflected in the financial statements, and HBM manufacturers' orders and prices will also quickly enter the income statement. More of the transactional layer of model applications is based on future expectations: subscription conversion, enterprise penetration rate, API revenue, and profit release after the future cost curve declines.
Efficiency Improvement Remains the Core Rationale for Multipolarity
Software investors and AI multi-polarity advocates are not without counterarguments. The core view of the efficiency camp is that the high current inference cost is only an early-stage phenomenon, and model optimization, caching, small models, self-developed chips, and higher cluster utilization will continue to drive down unit costs. As long as costs decrease rapidly enough, AI applications may still return to high-margin software logic.
This counterargument has a realistic basis. For certain mainstream models, the unit price has significantly decreased at the same or higher capability. OpenAI has disclosed that GPT-4o mini has reduced the cost per token by 99% compared to early text-davinci-003. While the pacing of different companies is not entirely consistent, Anthropic's recent focus has been more on the price-equivalent upgrades and model stratification, but the industry trend is still to provide greater capabilities at lower costs.

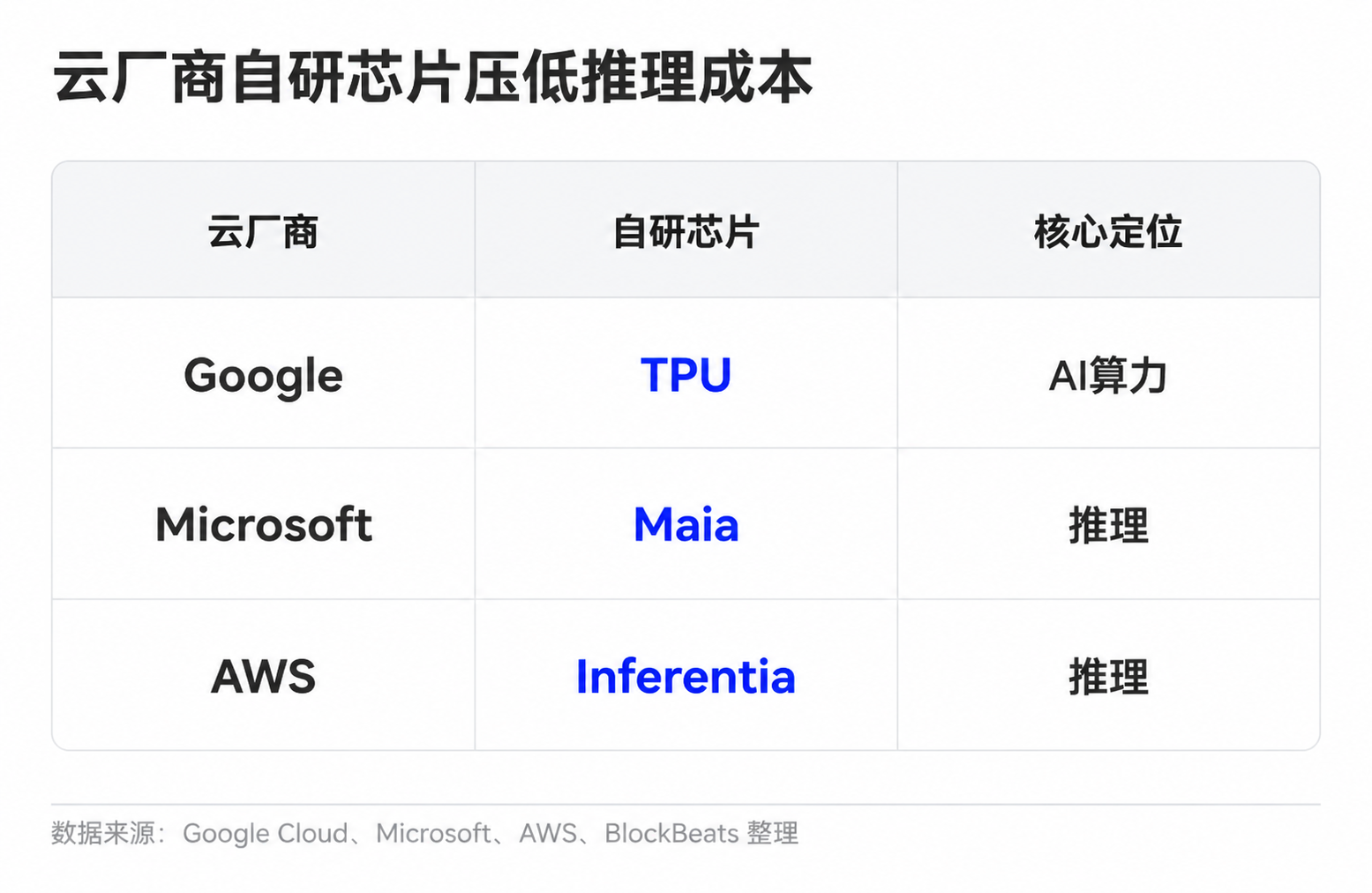
Model companies also have various ways to improve unit economics. Simple tasks are assigned to small models, common requests are handled through cache reuse, long contexts and complex tasks are given to more powerful models. Cloud providers, on the other hand, reduce unit compute costs through self-developed chips and cluster scheduling. Google has TPU, Microsoft has introduced Maia for inference, and Amazon is also advancing Trainium and Inferentia.
If we only look at technological advancements, there is indeed room for improvement in the profit margin of AI applications. Cheaper inference, better model routing, stronger compression capabilities—all these can allow the same $20 subscription to handle more usage. Light users, high-priced enterprise plans, API tiered pricing, and stricter usage limits can also improve overall unit economics.
The challenge lies in the fact that cost reduction is not the only variable. AI applications are moving from simple chatbots to heavier workloads. In the past, users may have only engaged in Q&A and text paraphrasing, but now more and more demands come from code agents, long document processing, video and multimodal generation, and enterprise automation workflows. These scenarios hold higher value but also consume more resources. The more useful the model, the more likely users are to entrust it with more complex and time-consuming tasks.
From here, the divergence becomes more specific: the speed at which inference costs decrease, can it surpass the growth in usage and task complexity. If unit costs drop rapidly, but average user consumption grows faster, the weighted gross margin of model companies will still be under pressure. Conversely, if model routing, caching, custom chips, and tiered pricing are effective enough, AI subscriptions may gradually shake off today's high-cost features.
Subscription User Count is not Gross Margin
The $20 breakdown chart should not be seen as the endgame. It is more like a valuation reminder at the current stage: when the market cannot yet see enough transparent data on model company gross margins, investors need to discount the assumption that "AI applications inherently equal SaaS."
For model companies like OpenAI and Anthropic that are not yet public, external investors find it challenging to access full financial statements. Financing materials, partner disclosures, cloud cost structures, enterprise package prices, API revenue share, and usage limits all become clues for evaluation. The truly valuable data is not how many paying users there are, but rather the proportion of light users and heavy users, whether enterprise clients are willing to pay higher prices for intensive usage, whether cloud billing costs are decreasing, and whether the decrease in unit inference costs can enter the company's gross margin.
Validation in the chain of public companies will appear more quickly in financial reports. NVIDIA's overall gross margin and data center revenue growth, TSMC's advanced process and packaging demand, HBM vendor prices and margins, cloud provider capital expenditure intensity—all will continue to reflect whether AI usage is still permeating towards the infrastructure end. If these indicators remain strong and there is a lack of evidence of gross margin improvement in the model application layer, the market will continue to assign a more certain valuation premium to the infrastructure.
Ultimately, for model companies to reclaim a higher valuation anchor, they need to prove not only that users are willing to pay $20 but that after intensive usage, these subscription fees can still leave behind enough gross margin. The next round of pricing discrepancies is likely not in the headline number of ARR but in whether inference costs, package restrictions, and enterprise payment prices can all align simultaneously.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia