Storage Is Not a Cost Center, It Is the Value Distribution System of the Bitroot AI Stack
Many teams realized, after going live for almost half a year, that the storage layer should have been chosen more carefully from the beginning. The data was not lost, the service did not stop, but the problem manifested itself in another way: the retrieval of archived training data became slower and slower, the tail latency of hot vector queries fluctuated from milliseconds to seconds, and when it was time to analyze an online incident, no one could clearly state which version of the training data the model was using at that time. At this point, the issue to solve is no longer about scaling up, but about three more challenging problems: who can prove that the data has always been available, who is responsible for the versions, and who will pay for the long-term costs.
Understanding storage as moving files from a centralized cloud to an off-chain network can still hold up in the NFT metadata era. However, once the business expands to AI training corpora, model weights, and vector indexes, this approach will quickly become outdated.
Most teams still consider storage as a logistical cost that should be minimized as much as possible, but this is precisely the most underestimated and easily misselected aspect: in an AI public chain, it is actually the value distribution layer that determines who controls the data and who receives the rewards. This article only addresses one question: how to build a verifiable, governable, and sustainable distributed storage solution in a scenario where AI is integrated with a public chain. The following text first breaks down the ability boundaries of three mainstream paradigms, then explains the special challenges of AI data, and finally delves into a five-layer deployment architecture and phased launch thresholds. The judgment criteria are mainly based on official protocol documents, relying as much as possible on verifiable information.
Taking Bitroot as an example, the more accurate positioning of the storage layer is as the foundation of the AI Stack's value distribution. On one hand, Bitroot provides a high-performance on-chain execution environment through parallelized EVM and Pipeline BFT, and on the other hand, through distributed training, inference networks, trusted execution, and AI asset management, it connects data, models, computing power, and Agent applications into a settlement network. In this network, storage is not an isolated module but the infrastructure that determines whether data can be claimed, models can be reproduced, computing power can be settled, and contributors can continue to receive rewards.

Full On-Chain and Full Centralization Are No Longer Viable in the AI Scene
In the past few years, the storage issue has often been simplified into a binary choice: either go fully on-chain or fully centralized. Neither of these paths is sustainable in the AI scene.
The pressure of full on-chain is very specific. Training data, model weights, inference logs, and vector indexes are generally high-volume with high-frequency updates. Even if sliced before being placed on-chain, it will still run into both throughput bottlenecks and cost curves simultaneously. Full centralization runs fast, but the trust foundation relied upon by verifiability, traceability, data sovereignty, and cross-party collaboration is very fragile. Once it involves multi-party accounting and rights confirmation, it cannot hold up.
The more critical change is that AI has turned storage from a cost item into a production factor. Who manages the data version determines who has the initiative for model iteration; the ability to prove data availability directly affects the scheduling of computing power and the settlement priority. The ability to monetize data assets relates to whether a team can establish long-term incentives in the ecosystem. At this point, the storage layer is no longer a logistics system but a value distribution system.
Therefore, a qualified storage architecture must answer four questions at the same time: whether the data truly exists and remains accessible, whether the relationship between data and model versions is traceable, whether permissions and rewards are governable, and whether the system can maintain a long-term balance between cost and performance.

Bitroot's Entry Point: Transforming AI Data from "Storable" to "Settlable"
This is precisely the position Bitroot needs to fill. As a high-performance Parallel EVM public chain oriented towards AI scenarios, Bitroot's storage narrative should not stop at "where the data is located" but should answer "how the data is proven, how it is called, and how it participates in accounting." Training corpora, model weights, vector indexes, and inference logs can reside in a distributed storage layer more suitable for large objects, but their hash commitments, version relationships, permission policies, call records, and revenue events need to form a unified on-chain evidence on Bitroot.
From this perspective, Bitroot's high throughput and low latency do not simply serve DeFi transactions but serve more granular and higher-frequency governance events in the AI Stack: dataset updates need to be anchored, model versions need to be registered, AI Agent calls need to be settled, retrieval result disputes need to be arbitrated, and storage node availability needs to be continuously challenged and rewarded. Only when the underlying chain can accommodate these events, will AI data assets not be locked in centralized databases or become unaccountable off-chain black boxes.

Three Mainstream Paradigms, None of Which Can Single-Handedly Cover the Entire Scenario
The competition of distributed storage has never been about who is the most advanced but about who is the most suitable in your data structure.
The Content Addressed Network solves the question of whether this is that piece of data, not who guarantees its online presence. According to the IPFS official documentation, CID is a content-hash-based identifier that does not rely on location addressing: the same content generates the same CID under the same encoding settings, and any change in the content results in a different CID. This feature naturally suits integrity validation, deduplication, and cross-system referencing, providing the underlying capability for data integrity. However, content addressing does not equate to economic persistence. CID addresses the identity issue, not the question of who ensures its continuous online availability. Many teams' first pitfall after going live is here: they have the CID technically but not a commitment to availability.
The Storage Market Network, on the other hand, achieves availability over time through an economic mechanism. According to the Filecoin documentation, the network establishes storage commitments through Proof-of-Replication and Proof-of-Spacetime, combined with continuous proof mechanisms. PoRep demonstrates the existence of a unique copy during initial sealing, while PoSt repeatedly proves its presence in subsequent periods. The proof period of WindowPoSt is typically organized in 24-hour cycles, further divided into multiple 30-minute proof windows. If a storage provider fails to submit a valid proof within the window, it triggers collateral forfeiture and storage capacity reduction. In this system, availability is an ongoing assessment item, not a one-time commitment after signing a contract. This contractual, auditable model is suitable for medium- to long-term archiving, backups, and data markets. However, it resembles proven long-term warehousing rather than a naturally low-latency online service. Placing high-frequency online queries directly on it will be dragged down by tail latency.
The Permanent Storage Network takes a different path, exchanging one-time payments for immutable history. According to the Arweave protocol and whitepaper, a portion of the upload fee goes into the Storage Endowment, used to cover long-term storage incentives. By front-loading long-term sustainability into the billing model, it does not rely on subsequent renewal habits. This model is suitable for historical archiving, critical credentials, and copyright materials—immutable records. The limitation is also evident: permanence does not automatically mean high concurrency and low latency. In practice, caching, gateways, or near-line indexing layers need to be added to meet user-side real-time experience.
Aside from these three basic paradigms, there are two common engineering combinations worth considering. One is a hybrid of data availability layers and object storage, where data publishing and availability proofs are more standardized, but at the cost of complex cross-layer collaboration and high interface governance. The other is multi-cloud with edge coordination, offering better low latency and disaster recovery but posing challenges in cost governance and consistency management.
Regardless of the choice, a protocol that tries to cover all scenarios is not feasible in engineering. An effective approach is to combine based on data type: separate persistence, retrieval latency, and compliance, match them with appropriate layers of capability, and then unify them through on-chain anchoring and governance layers.
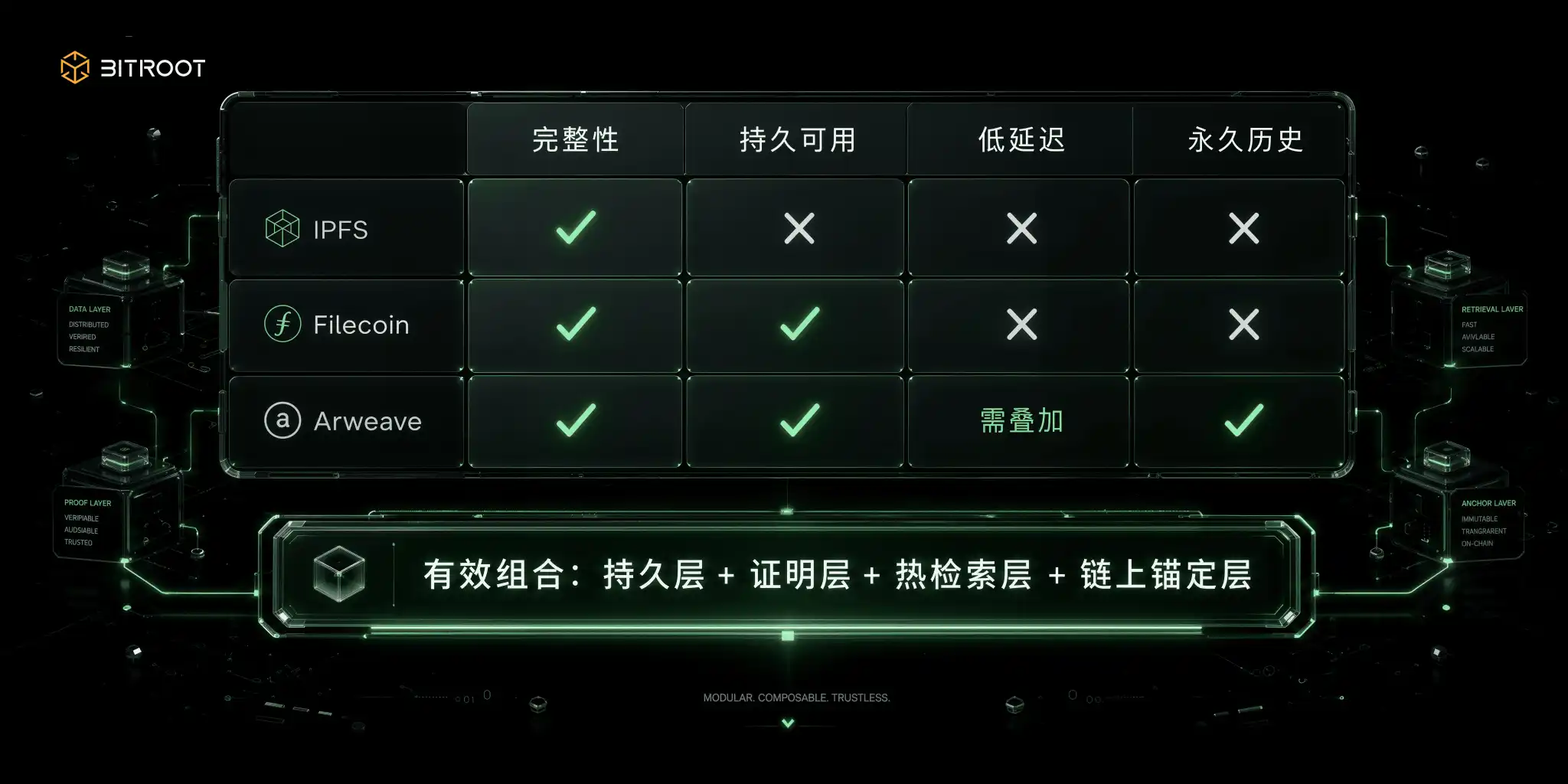
The space selection of Bitroot should also be based on this combinatorial logic: not to replace IPFS, Filecoin, Arweave, or object storage with each other, but to place them in different responsibility layers. Content addressing is used for data identity and integrity, storage proofs for long-term availability, the immutable layer for critical history and credentials, the hot retrieval layer for AI application experience, and the Bitroot on-chain layer to uniformly handle version anchoring, permission policies, invocation settlements, and dispute resolution. In other words, Bitroot does not need to be the physical repository of all data but needs to be the trusted ledger for the AI data value flow.
The Challenge of AI Storage Lies Not in Storing Files, But in Managing the Production Pipeline
In an AI scenario, stored objects are divided into at least four categories: training data, model weights, vector indexes, and inference logs. The lifecycle, access patterns, and value density of these four types of objects are completely different. Managing them with a single strategy might be convenient in the short term but will inevitably lead to governance issues in the long run.
The trouble with training data lies not in its capacity but in version drift. Many teams equate the problem of training data with the cost of storing terabytes, but the actual challenge is drift: any change in cleansing rules, sample selection thresholds, or labeling criteria will cause the model's behavior to change. Without binding data versions to model versions, offline evaluations become difficult to reproduce. According to the model and data tracking practices of MLflow, binding training runs to data versions is a prerequisite for reproducing experiments. This principle still holds true on the blockchain: not all raw data needs to be uploaded to the chain, but version commitments, key digests, and source fingerprints must be anchored on-chain. From an engineering perspective, at least three identifiers must be bound: data version, training run, and model version. If one is missing, tracing online issues will devolve from evidence verification to guessing causes.
The issue with model weights often lies not in their downloadability but in who manages the invocation boundaries. When a model enters production, it usually undergoes several states: grayscale, primary use, rollback, retirement. Without a standardized registration and authorization system, online invocations become an unauditable black box. A mature model registry will concurrently record lineage, version aliases, signing constraints, and audit tags. For on-chain systems, a model version should not only be a file hash but should also be linked to permission policies, revenue distribution, and responsibility boundaries.
The challenge of vector indexing is concentrated in one area: consistency after hot-cold layering. Vector retrieval faces an inherent contradiction, with low latency and low cost in conflict: the hot layer relies on memory or high-performance index services to ensure online response, while the cold layer relies on object storage to contain long-term costs. Without unified metadata and synchronization policies, the two layers will quickly diverge, eventually leading to the problem of the same query returning different semantic results on different nodes. Therefore, a vector system must support two things: a traceable index construction process and the ability to cross-check the hot layer index version with the cold layer master data. This is also the issue that verifiable retrieval discussed later aims to solve.
For a provenance log to achieve privacy, auditability, and compliance simultaneously is challenging. It serves as both a security audit material and a privacy risk source: retaining full plaintext data poses compliance risks, while not retaining any data eliminates the ability to conduct incident postmortems. The feasible approach is a three-layer overlay: store data after anonymization, anchor hashes on the chain, access requires audit authorization, achieving both tamper resistance and revocable access in a layered manner.
In Bitroot's AI Stack, these four object types can correspond to four governance actions: version anchoring and source registration for training data, asset registration and authorized invocation for model weights, hot-cold tiering and consistency proof for vector index, and anonymized storage and audit commitment for provenance logs. They do not need to be on-chain in the same way but they all need to form a unified asset ID, version lineage, and invocation events on Bitroot. This way, data assets, model assets, and Agent applications can potentially form a reusable business loop.

Verifiability is the baseline, while usability proof is the watershed
A storage commitment without usability proof is essentially meaningless in a production environment. For distributed storage to be deployed in production, it must pass at least three gates: integrity proof, availability proof, and behavior auditability; once entering the AI retrieval scenario, it must pass the most challenging gate, retrieval proof.
Integrity proof relies on content addressing plus Merkle commitment. Content addressing ensures data fingerprints remain stable, while Merkle commitment ensures partial verifiability. The engineering significance lies in being able to verify a subset of objects at the shard level, avoiding full read every time. For large model weights, corpora, and multimedia data, this directly determines the verification cost.
Availability proof relies on challenge mechanisms and sampling verification. Filecoin's practice has shown that availability is not just a verbal SLA but a periodic challenge plus on-chain proof, abstracted into a generic architecture as passive spot checks, active patrols, and failure penalties: nodes must respond to challenges within a set window, otherwise triggering penalties or weight loss. The same approach has been further developed in data availability. According to Celestia's data availability sampling design, the data expands from a k×k to a 2k×2k matrix, where light nodes establish high-confidence availability through multiple rounds of random sampling and probability accumulation, without needing to download entire blocks of data. This provides an enlightening idea for AI scenarios: facing massive objects and high-concurrency access, not all availability needs to be verified through full downloads; statistical confirmation is more practical in large-scale systems.
Behavior auditability relies on on-chain anchoring plus event tracing. The most challenging aspect of a storage system to manage is actually behavior: who uploaded what, who changed policies, who triggered migrations, who invoked sensitive models and when. If these behaviors are not aggregated into a unified event flow, disputes will rely on hearsay when they occur. What governance layers need to do is not to move all details onto the chain but to hold a minimal, definitive, and verifiable evidence set when disputes arise.
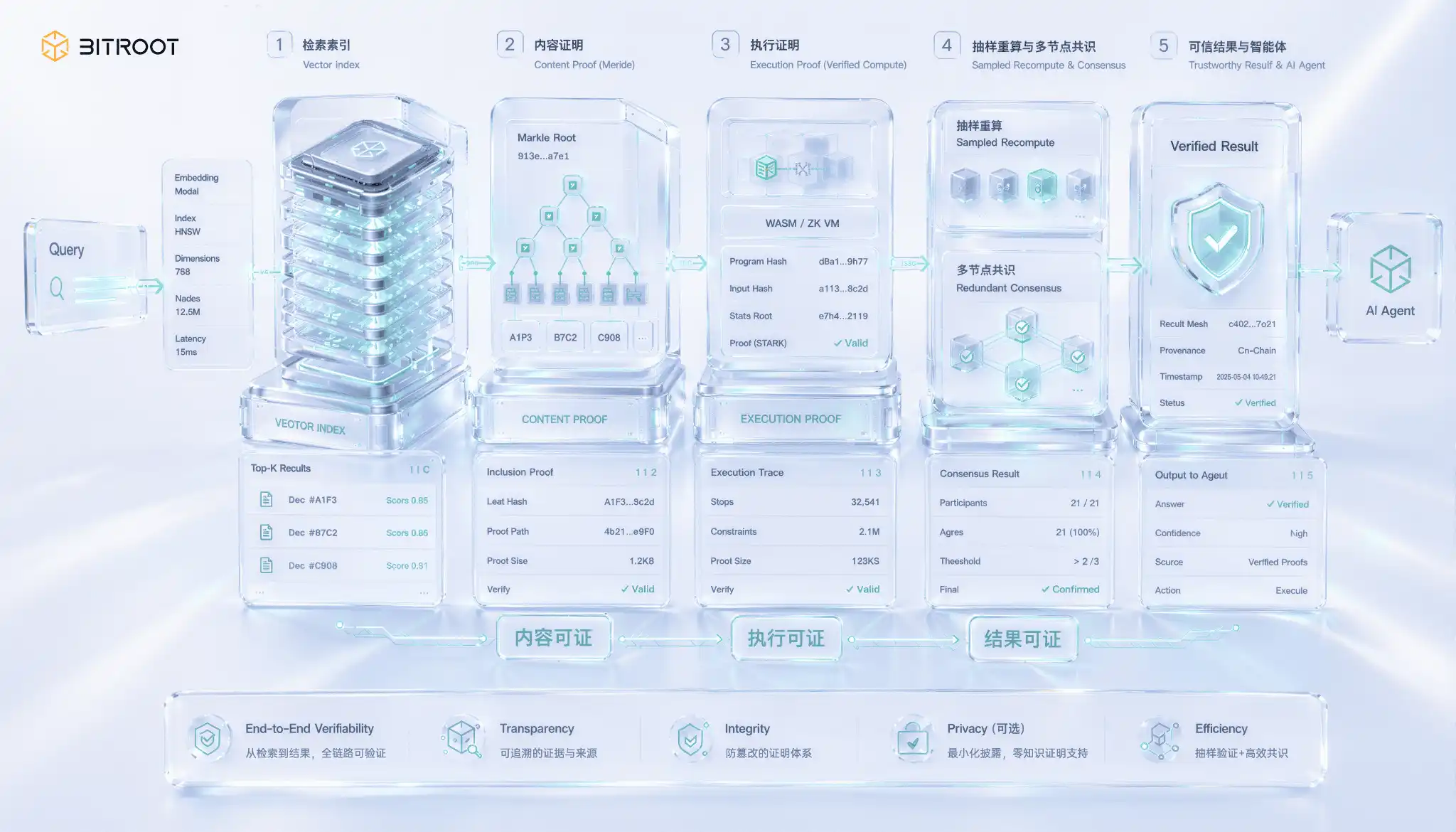
Provenance of retrieval is a unique challenge in AI scenarios and also the most difficult one. The problem lies in an easily overlooked gap: getting a result does not equate to getting the correct result. A vector retrieval node could easily use an outdated index, or even skip the true nearest neighbor, to give you a seemingly reasonable top-k result, and you would have no way to distinguish this just by looking at the return value. The output of semantic retrieval itself lacks self-evidence, errors will not be reported but will silently decrease recall quality and model performance. When retrieval results are to be used for settlement, authorization, or on-chain decisions, this gap transforms from a quality issue to a trust issue.
Breaking down the proof of retrieval, it is actually a three-tiered escalating guarantee. The first tier is content proof, proving that the returned vector indeed belongs to a certain committed index version, achieved by establishing an authenticated data structure for the index, anchoring the index root on-chain with a Merkle commitment, and providing an inclusion proof when returning results to ensure that nodes have not fabricated or tampered with data. The second tier is execution proof, proving that this query did run on the committed version and not on a privately modified index, which requires bringing the query process into the realm of verifiable computation. The third tier, the most difficult, is the result proof, proving that the returned top-k under a given metric is indeed the closest ones, rather than missing closer neighbors, fundamentally requiring a proof of correctness for approximate nearest neighbor search.
At a production scale, providing strict result proofs for high-dimensional approximate nearest neighbor search is still a cutting-edge topic. Though cryptographic tools such as zero-knowledge proofs are advancing, the proof overhead of high-dimensional vector operations is far from being suitable for large-scale online use. The pragmatic engineering solution is to layer backstops instead of attempting to achieve everything at once: first anchor the index version and construction parameters on-chain to ensure traceability; then recompute queries through sampling, proportionally selecting online queries to rerun on trusted copies and compare results, using statistical confidence instead of individual proofs; simultaneously have multiple independent nodes redundantly retrieve and vote on returned results to increase the cost of single-point cheating; only when discrepancies arise in verification or consensus, escalate to full recompute for disputed queries and on-chain adjudication. This approach aligns with the philosophy of sampling verification prioritized in availability proofs: in large-scale systems, statistical confirmation plus dispute escalation often proves more feasible than rigorous individual proofs.
For Bitroot, verifiable retrieval is not merely an isolated storage function but a part of AI Agent's trusted execution. If an on-chain Agent relies on external knowledge bases, model weights, or vector indices for decision-making, the system should be able to answer at least three questions: which data version it reads, which model version it invokes, and whether the returned results come from a registered index version. Bitroot can compress this evidence into on-chain verifiable events, transforming the behavior of the Agent from merely "seemingly intelligent" to "traceable, disputable, and settleable."

The Real Issue of Technology Selection: It's Not About Choosing a Protocol, But Building a Combination
Many solution evaluation failures are due to a misrepresentation of the problem. The correct approach is not whether we should use a specific protocol, but rather what our data combination is, what our key performance indicators are, and what our constraints are. It is recommended to follow four key actions.
Start by taking an inventory of data assets. At the very least, differentiate between state data, object data, retrieval data, and audit data. Create an inventory template with fixed fields, with a minimum of eight items: data type, daily increment, peak concurrency, read/write ratio, retention period, compliance level, target latency, and cost ceiling. Once the fields are standardized, cross-team technology selection discussions will be much more efficient.
Next, define service level objectives. Set specific values for P95/P99 latency, recovery time objective (RTO), recovery point objective (RPO), availability targets, and cost ceiling per TB, as without these benchmarks, all subsequent discussions will lack a reference point.
Then establish a capability mapping. Map capabilities such as permanent storage, periodic availability proof, low-latency retrieval, and access governance to different technology layers, rather than relying on a single layer to cover all.
Finally, set migration thresholds. Determine which data can undergo a transitional period of centralized hosting, what metrics trigger migration, and when decentralized replacement must be completed. A practical approach is to set dual thresholds: if the cost per TB exceeds the budget for two consecutive statistical periods, or if the P95 latency exceeds the target for two weeks in a row, an automatic architecture migration review is triggered. Without thresholds, there is no governance, and the transitional period may become a permanent state.
Implementation Plan: Five-Layer Architecture, Closing the Loop of Storage, Retrieval, and Governance
The value of an architecture lies not in the number of layers but in whether it can form a verifiable closed loop. Building on the previous framework, the solution converges into five layers: the on-chain anchoring layer, object storage layer, index retrieval layer, availability proof layer, and key permission layer. The goal is to turn verifiability into a default capability, configurability into high-performance, and governance into an executable process.
In the context of Bitroot, these five layers can be further understood as a storage governance module of an AI Stack: Parallel EVM provides high-frequency anchoring and settlement capabilities, Pipeline BFT offers low-latency determinism, distributed storage networks handle large objects and historical data, the index retrieval layer serves AI Agents and application calls, the availability proof layer transforms node service quality into reputation and rewards, and the key permission layer connects user sovereignty, privacy protection, and commercial model authorization.
The on-chain anchoring layer only stores the minimal required state: data commitment, version fingerprint, summary of permission policies, and settlement events. Large objects are not stored on-chain; instead, what goes on-chain are proofs of the existence and correct version of these objects. This approach maintains on-chain verifiability without compromising throughput due to large file sizes.
In the context of Bitroot's architecture, the on-chain anchoring layer is not just a place for "recorded hashes," but a shared entry point for AI asset registration, permission governance, revenue distribution, and dispute resolution. Data sets, model weights, vector indexes, and inference logs can all be stored off-chain in the most suitable way, but their version commitments, authorization status, invocation records, and revenue attribution need to enter Bitroot's on-chain state. This way, off-chain storage is responsible for carrying the volume, while Bitroot is responsible for carrying trust.
The object storage layer carries real data and adopts a hybrid strategy of erasure coding plus replication: objects of high value and low access frequency emphasize fault tolerance, while objects of medium value and high access frequency emphasize retrieval efficiency. This strategy is not a static configuration and needs to be dynamically adjusted based on access patterns and business levels.
The index retrieval layer integrates metadata indexing and vector indexing into a unified directory, with the hot layer handling online retrieval and the cold layer handling archival and reconstruction. All index versions must register the source data version and construction parameters; otherwise, index drift cannot be traced.
The availability proof layer quantifies node behavior. Success rates in responding to challenges, response latency, and repair success rates all contribute to a reputation score, which is then tied to reward distribution, avoiding rewarding only capacity without rewarding availability.
The key permission layer controls access and compliance. Highly sensitive data uses hierarchical keys and time-limited authorization, inference logs use anonymized storage plus audit replay, and model invocations use revocable licenses. Permission operations themselves must also be logged to prevent configuration drift.
These five layers form a closed loop at the execution level, not a one-way pipeline: after data access, it is first slice encoded into the object layer, indexed after writing, and anchored on-chain; online queries go through the hot layer, falling back to the cold layer if cache misses; while returning results, integrity verification and permission checks are triggered simultaneously, with key actions entering settlement and auditing. The real value of this chain lies in the fact that any node, at any time, can answer four questions: where did the data come from, what is the current version, who has access rights, and can the system prove it is available.
This is also a key reason why Bitroot is suitable for handling AI storage governance. AI Agent calls, model version switches, data authorization changes, and retrieval result disputes are not low-frequency backend operations but on-chain events that will continue to occur as the application grows. If the underlying chain cannot provide a low enough confirmation latency and high enough throughput, storage governance will ultimately be forced back to off-chain tables and manual reconciliation. Bitroot's Parallel EVM and Pipeline BFT combination provide value not only in terms of higher TPS but also in enabling these high-frequency governance events to be anchored, settled, and audited in real time.

Who Pays the Bill: Letting Availability, Not Capacity, Determine Revenue
Storage needs to be sustainable in the long run, and incentives must be aligned with availability rather than capacity. Only rewarding capacity is equivalent to indirectly encouraging nodes to stack hard drives and provide light services. Filecoin has corrected this with a mechanism: it has introduced the concept of quality-adjusted power to let sectors that have taken on real storage deals, especially verified effective deals, the minimum measurable unit of storage space, receive higher weight in power estimation. This shifts the reward towards capacity that actually provides services, rather than purely towards sealed empty capacity. This idea is worth any self-built incentive layer learning from.
To operationalize it into an executable reward function, at least four dimensions must be taken into account simultaneously, with each of their weight logics clearly defined. Capacity determines the base share, answering how much space you have committed to. Uptime and response latency determine the service quality factor, answering whether this space is truly available when needed, and this should carry a higher weight, otherwise availability becomes a mere slogan. Data recovery success rate determines disaster recovery trustworthiness, answering whether replicas can be rebuilt after a node failure, directly impacting the survival of long-tail data. Data value density determines demand-side bonus, applying a differentiated multiplier to high-value datasets and high-demand models, allowing scarce and frequently accessed data to receive higher rewards. Rewards should be given to provable services, not declared capacity.
Positive incentives alone are not enough; constraining side mechanisms such as staking, penalties, and arbitration must also be in place, and they must satisfy an underlying inequality: the expected benefit of cheating must be lower than the expected cost of punishment; otherwise, any proof mechanisms will be economically bypassed. Staking makes nodes commit a cost to their availability commitment, and the staking scale should be proportional to their committed power and data value; in Filecoin's design, storage providers need to deposit an upfront collateral based on committed power, triggering a fault fee if they go offline within the proof window, and a heavier termination penalty if the sector is permanently forfeited. The significance of this tiered punishment system is to treat short-term outages and malicious exits differently. Arbitration uses on-chain evidence to drive dispute resolution: when a user claims data is unavailable and a node claims to have provided normal service, challenge records, sampling proofs, and event logs constitute machine-readable arbitration evidence, compressing disputes that originally required manual intervention into a single verifiable on-chain judgment.
In an AI scenario, another layer of more challenging governance needs to be added on top of this: how to split three-party benefits. A model that is repeatedly called has data contributed by data contributors, training contributed by model contributors, and hosting borne by storage nodes in the background; all three parties contribute to the final call value, but their contributions are difficult to observe directly. A feasible approach is to attribute value to measurable on-chain events: calls are billed per invocation and settled automatically, data and models are bound to each call by version fingerprints and lineage, then automatically split according to pre-programmed revenue sharing ratios to avoid disputes after the fact. Complementary to this are blacklist and penalty mechanisms: for malicious data uploads, copyright infringement, model misuse, once arbitrated, the collateral is seized, and future earnings are frozen. Otherwise, there will be a counterintuitive result: the more successful the securitization, the more disputes over revenue sharing and ownership, ultimately undermining ecosystem trust itself.
Compliance is not a post-launch patch but a constraint during the architecture phase: the security baseline consists of end-to-end encryption, layered key management, and periodic rotation, overlaying hash verification with Merkle commitment to ensure verifiable downloads, then using multi-copies and erasure coding for joint disaster recovery to cover fault tolerance; on the privacy side, minimum permission access control is done based on data classification, supporting revocable, one-time, and time-limited authorizations, with end-to-end traceability of critical access and operations to facilitate audit replay. Compliance is also the most easily postponed and the most costly part: data localization and cross-border data transfer policies should be configurable, and there should be standard process interfaces for deletion, access, audit requests; the most thorny issue is the natural conflict between tamper resistance and deletability, with a feasible solution being cryptographic erasure with index invalidation: destroying the key makes the ciphertext irretrievable, and making the index invalid makes the data unsearchable, meeting deletion requirements while retaining on-chain records. There are three key stages from pilot to production: first establish the minimal trusted closed-loop, stabilize object storage, on-chain anchoring, integrity verification, and basic monitoring, with acceptance criteria focusing on availability, read/write success rate, anchoring consistency with object versions, and rehearsed fault recovery; then proceed with AI assetization and index governance, introducing data set and model asset management, version lineage, hot-cold tiering of vector indexes, model authorization invocation, and registration of training data sources, with acceptance criteria including traceable training, auditable and rollback-capable models, meeting hot-tier latency standards, and manageable index rebuilding impact; finally, implement verifiable retrieval and automated governance, introducing challenge proofs, policy migration, and automated rewards and penalties, with acceptance criteria covering availability proof coverage, risk response latency, cost reduction per unit, and traceable and rollback-capable policy changes. The metrics system serves as a strategic system rather than a display report. If only technical items are written without business results, the storage solution will collapse into a pure cost center; it is recommended to have three layers: basic technical metrics (availability, P95/P99 latency, throughput, RTO/RPO, error rate) answer whether the system is healthy, AI-specific metrics (traceability of training data, reproducibility of models, verification coverage of inferences, index consistency) answer whether the model quality is governable, and business outcome metrics (data supply growth, decreasing call cost, node activity, asset transaction scale) answer whether the system is creating value. There should be a mapping relationship between the three layers, and the true purpose of metrics is to provide input for strategic optimization, not just for display reports. The most common five failure points can basically be avoided in advance: doing storage without version control, data availability does not mean usability, and usability does not mean reproducibility; focusing only on capacity without looking at availability proof, rewarding based on capacity will induce capacity stacking and light services; although hot-cold tiering is implemented, synchronous strategy is not, and index version synchronization and invalidation handling are not closed-loop; delaying compliance strategy, the later the response to permissions, logs, anonymization, and deletion, the higher the cost; transitional architecture lacks an exit mechanism, transitioning from centralization to decentralization is a reasonable path, but lacking migration thresholds will solidify the transitional state and deviate from the original intention.
Bitroot's Complete Closed Loop: From Data, Model to AI Agent
In this closed loop, Bitroot can transform every key action of AI assets into a settlement event: dataset registration, model version release, vector index reconstruction, AI Agent invocation, inference log anchoring, permission authorization and revocation, dispute challenge, and arbitration result. The blockchain does not need to carry all the data but must carry the minimal evidence of these actions. Only in this way can the value relationship between data, models, computing power, and applications move from mere verbal promises to programmable accounting and auditable governance.
Integrating this mechanism into Bitroot's operations and ecosystem expansion, storage incentives should not be designed as a standalone hardware subsidy but should be part of the AI Stack's value flow: data contributors earn rewards for their data being trained or called, model contributors earn rewards for model services, storage and retrieval nodes earn rewards for providing continuous availability and low-latency services, and validation and challenge nodes earn rewards for detecting unavailability, index drift, or permission anomalies. This way, Bitroot's economic system rewards not for "having uploaded" but for "continuously and provably useful."
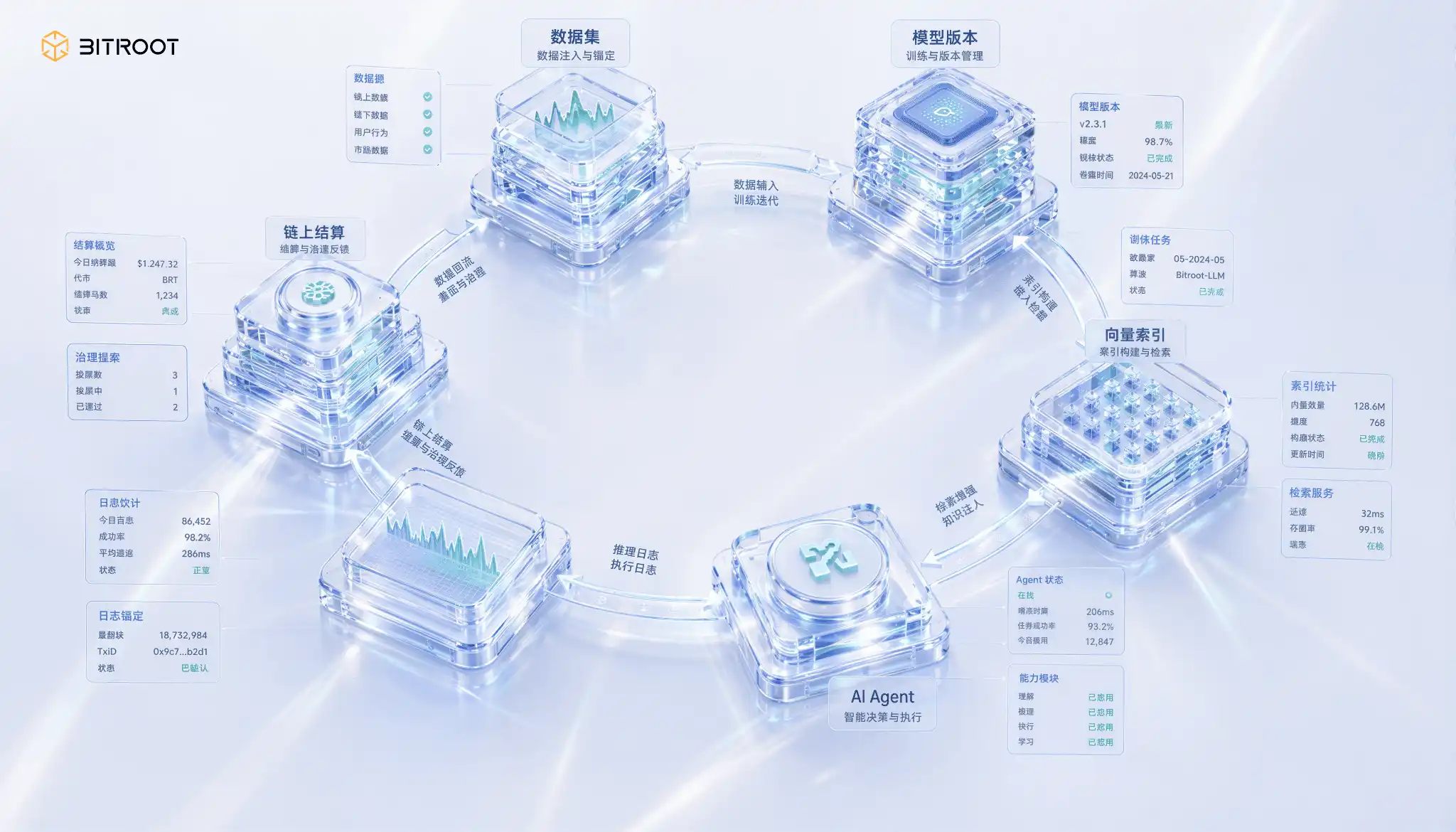
Storage is Not a Cost Center, But a Trust and Value Distribution System
What distributed storage needs to address in the AI era is not to replace a specific object storage product or pursue a decentralized narrative, but rather four tougher challenges: long-term available trust proofs, governance order for cross-party collaboration, data and model responsibility chains, and sustainable economic incentives.
A single-protocol single-layer architecture cannot cover these goals. A more practical approach is a compositional architecture: content addressing ensures integrity, storage proofs ensure time-based availability, the archival layer preserves critical history, the hot layer maintains online experience, on-chain anchoring ensures governance and settlement verifiability. This is not a compromise but engineering rationality. The deployment focus is not on the most feature-rich solution but on establishing the closed loop first. Start by running the minimal viable trust loop, then gradually add layers for AI assetization, verifiable retrieval, and automated governance.
Condensing this approach into a week of action involves just three steps: complete an eight-field data inventory on the first day, run a minimal link from access, storage, retrieval to validation in a real business domain on the third day, and conduct a migration threshold retrospective meeting on the seventh day based on P95 latency and unit cost. By completing these three steps, the team transitions from conceptual consensus to engineering consensus.
It's also crucial to recognize a realistic boundary: regardless of the protocol combination used, there are trade-offs between cost, latency, and durability, and there is no single optimal answer that fits all businesses simultaneously. A truly sustainable solution comes from continuous iteration within clear boundaries, rather than a long-term static configuration decided in one go.
The future elimination of a project is often not due to insufficient TPS, but the inability to explain the data responsibility chain. In the era of AI public chains, storage means not just putting data in, but ensuring that data can be proven at any moment.
Conclusion
In the true competition of AI public chains, the final showdown will not only be about comparing TPS, Gas, or confirmation times. Performance is the entry point but not the endgame. As we enter the era of AI-native applications, on-chain systems must bear not only transactions but also data versions, model calls, computing power scheduling, inference records, agent behavior, and multi-party profit distribution.
This is also Bitroot's assessment of the storage layer: storage is not just an ancillary module but the closest layer to the source of value in the AI Stack. Whether data can be proven, models replicated, calls audited, profits automatically allocated determines whether a decentralized AI network truly possesses long-term vitality.
What Bitroot aims to build is not just a chain that pursues faster execution but an infrastructure that allows AI assets to be confirmed, called upon, settled, and governed. Parallel EVM and Pipeline BFT address the capacity for high-frequency on-chain events, distributed storage and verifiable mechanisms tackle the trust foundation of AI data and models, and programmable accounting and on-chain governance transform contributions into continuous economic incentives.
When AI agents begin to act on behalf of users, when models and data become tradable assets, when computing power, storage, and inference services enter the same value network, storage will no longer be a matter of "where to put the file."
It will serve as the trust foundation of an AI public chain and the value distribution system of the next-generation intelligent network.
In Bitroot's view, the truly crucial factor in the future is not who owns the most data but who can make data provable, callable, traceable at any time, and ultimately participate in value settlement.
About Bitroot
Bitroot is a Layer 1 public chain project focusing on parallel execution and AI-native architecture. Bitroot adopts an EVM-compatible technical route and explores providing a high-performance, low-cost on-chain execution environment for AI agents, DeFi, and Web3 applications through parallel execution mechanisms, consensus optimization, and AI-related interface design.
Welcome to join the official BlockBeats community:
Telegram Subscription Group: https://t.me/theblockbeats
Telegram Discussion Group: https://t.me/BlockBeats_App
Official Twitter Account: https://twitter.com/BlockBeatsAsia